video captioning 是一项跨模态任务,输入视频,输出自然语言来描述视频内容。video captioning的pipeline如图所示。首先使用预训练的模型(如resnet)提取视觉特征,然后通过编码器对视觉特征进一步融合,最后使用解码器生成句子。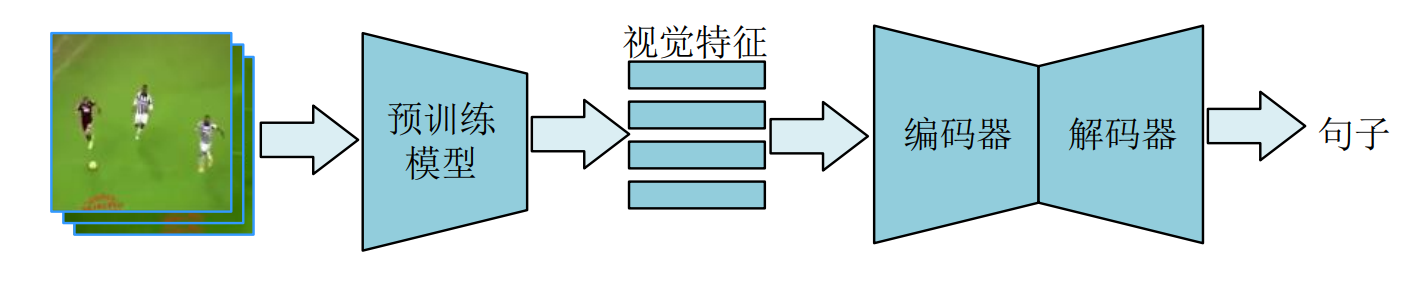
以下结合论文阐述video captioning上一些重要的工作,image captioning 与 video captioning 有着高度相似,因此以下会参杂着一些image captioning的文章。
Show and Tell: A Neural Image Caption Generator[2015]
image captioning方向的早期工作,使用预训练的VGG模型提取图像特征,输入到LSTM中生成句子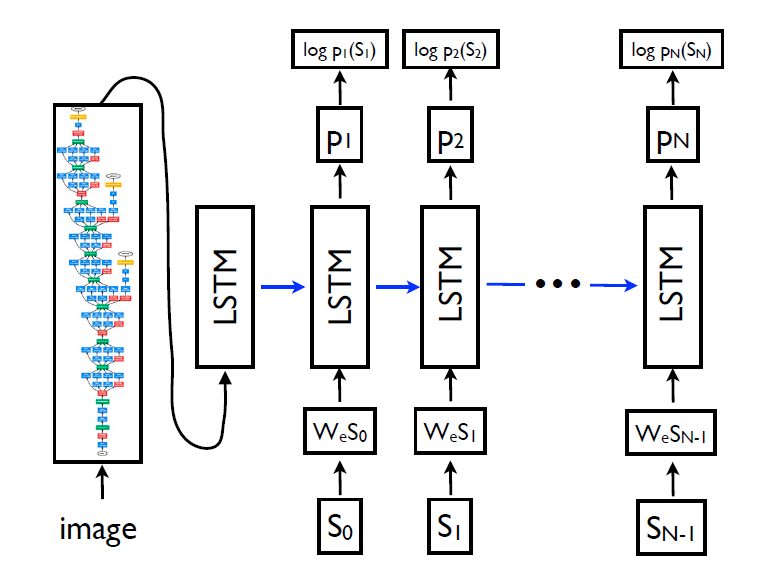
Sequence to Sequence – Video to Text[2015]
video captioning方向的早期工作,同样是使用预训练模型提取图像特征后输入到LSTM中生成句子,与 image captioning 不同的是使用了双层LSTM来融合不同视频帧的特征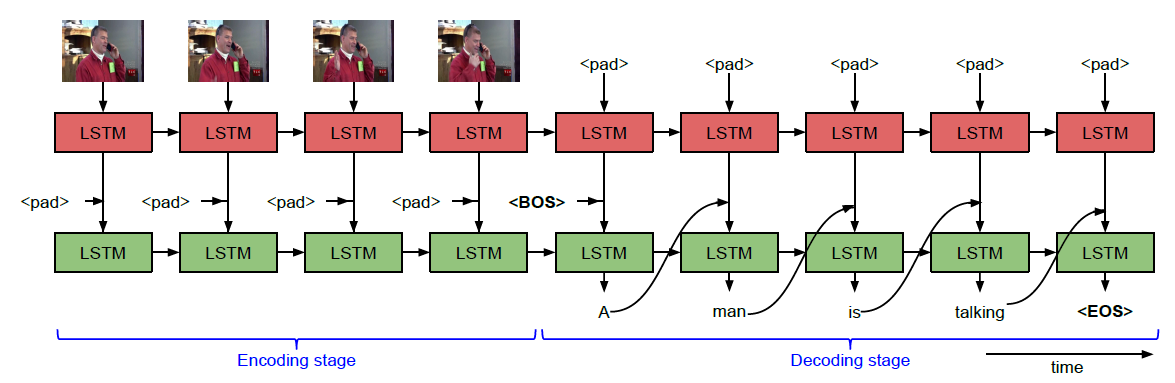
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention [2016]
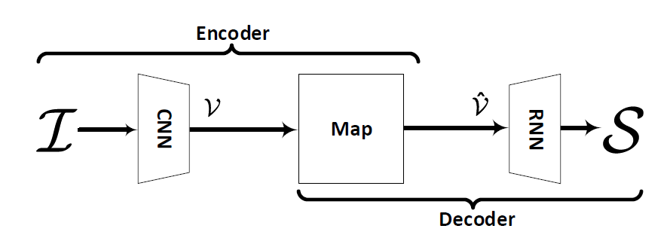
将注意力机制引入到image captioning,其出发点是生成每个词的时候提取最相关的视觉特征。注意力机制是一个重要的研究点,结合任务产生了各种不同的注意力机制。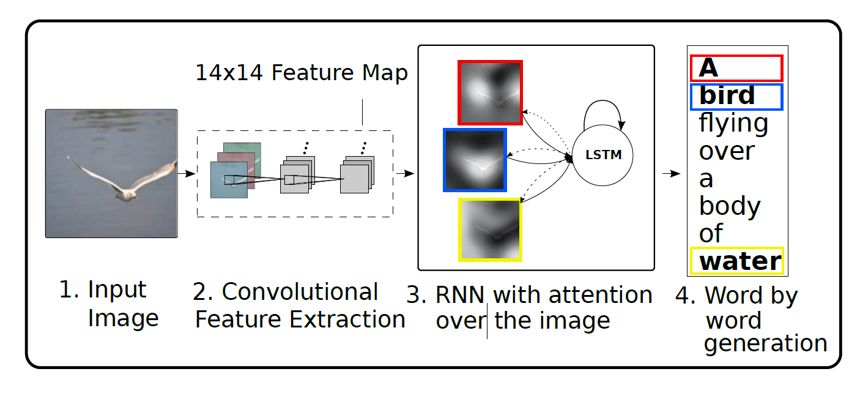
Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning [2017]
注意力机制的改进之一,出发点在于句子中的连接词是与视觉特征无关的,更多取决于句子中的语法结构,其动机图如下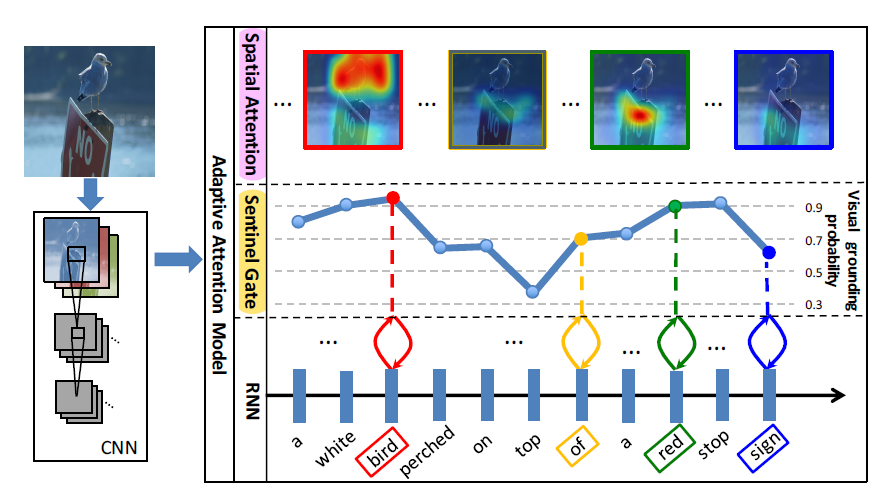
其实现方式也值得借鉴,直接增加一个表示句子内容的特征矢量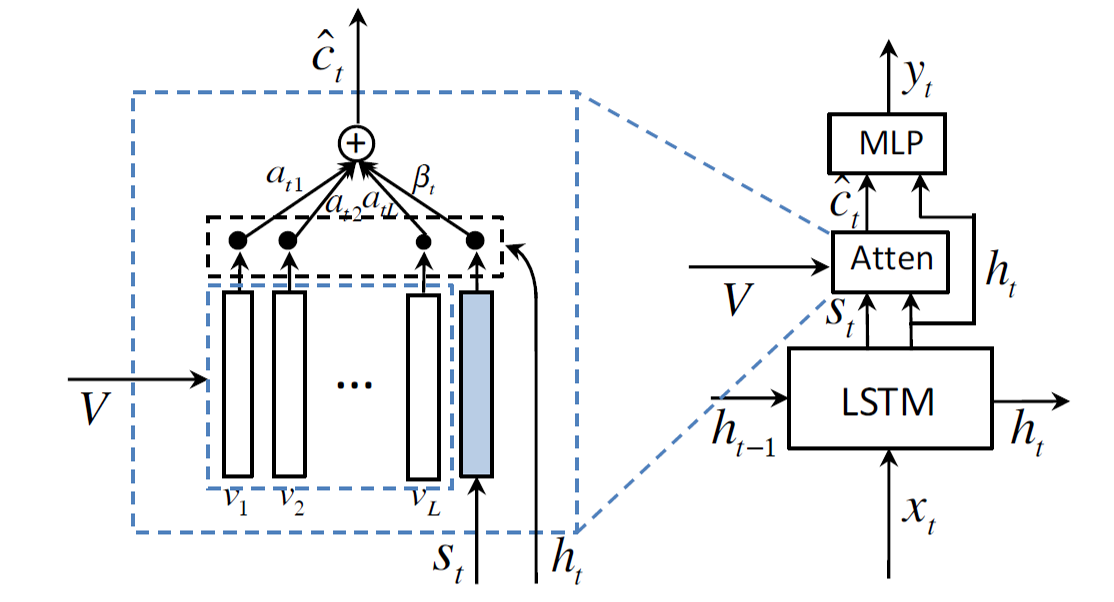
Attention on Attention for Image Captioning [2019]
同样是对注意力机制的改进,并且效果还行,被后续挺多文章引入到框架中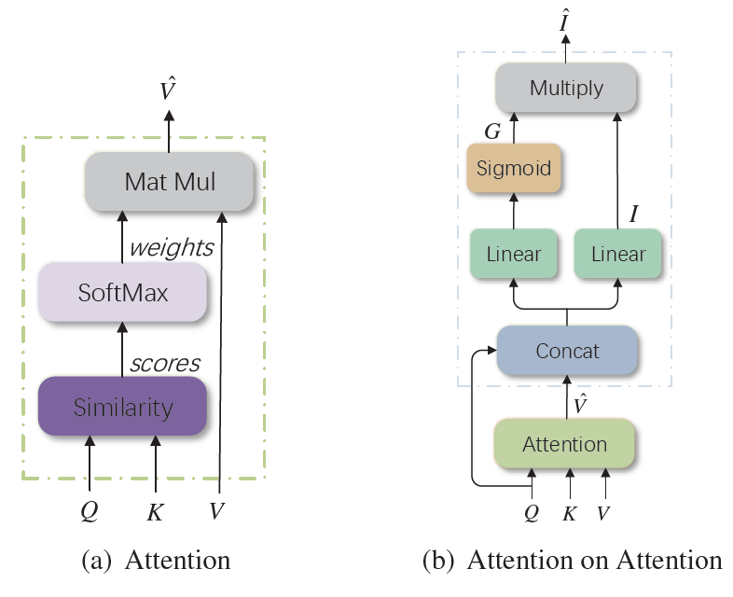
关于动机,直接引用原文的措辞:to measure the relevance between the attention result and the query
另外还有很多其他关于注意力机制的改进,如X-Linear Attention Networks for Image Captioning [2020],Motion Guided Spatial Attention for Video Captioning [2019],More Grounded Image Captioning by Distilling Image-Text Matching Model [2020]等,本文不作一一阐述。
Reconstruction Network for Video Captioning [2018]
在结构上面,该文在编码器解码器后添加了重构器形成了闭环,即通过生成的文字特征重构视觉特征。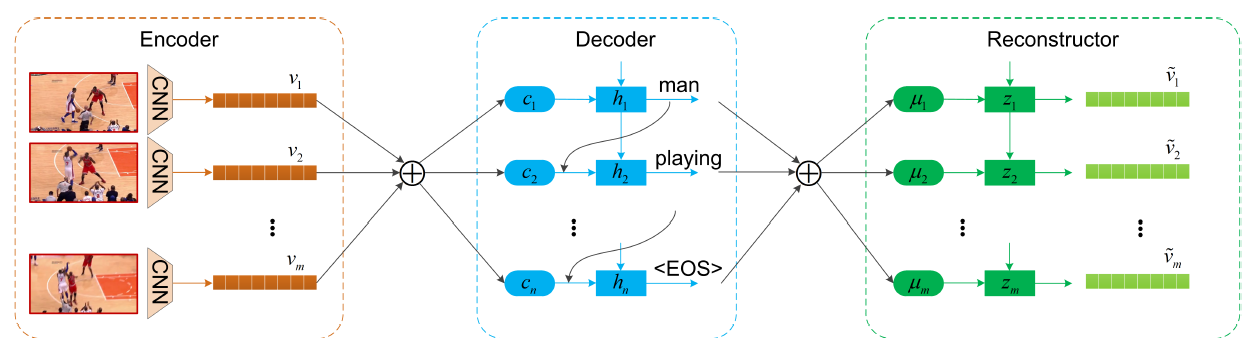
Meshed-Memory Transformer for Image Captioning [2020]
随着transformer在自然语言方向的应用,近年transformer也成为了image captioning和video captioning的主流框架。![]()
Unified Vision-Language Pre-Training for Image Captioning and VQA [2019]
统一框架也是研究热点,如将captioning和VQA融合到一个框架中,关于统一框架建议先看 Unified Language Model Pre-training for Natural Language Understanding and Generation [2019]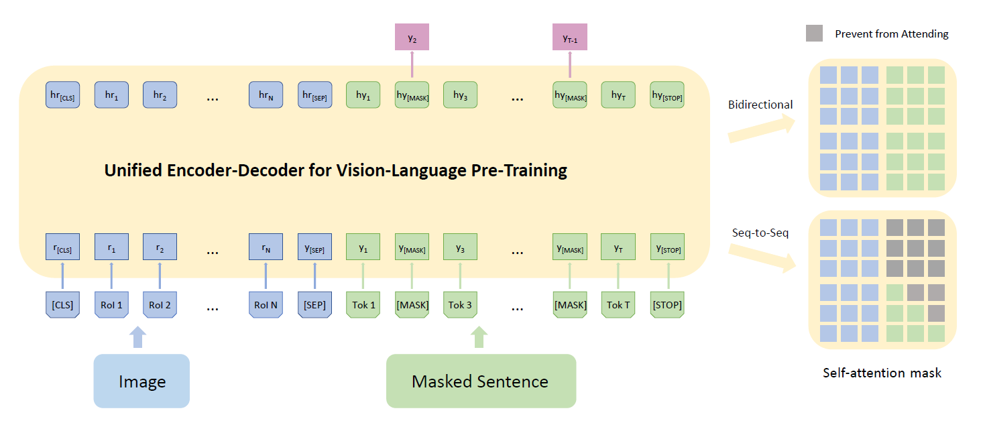
Towards Unsupervised Image Captioning with Shared Multimodal Embeddings [2019]
除了使用监督学习的方式,无监督学习框架在captioning也有应用,可以参考 unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks[2017]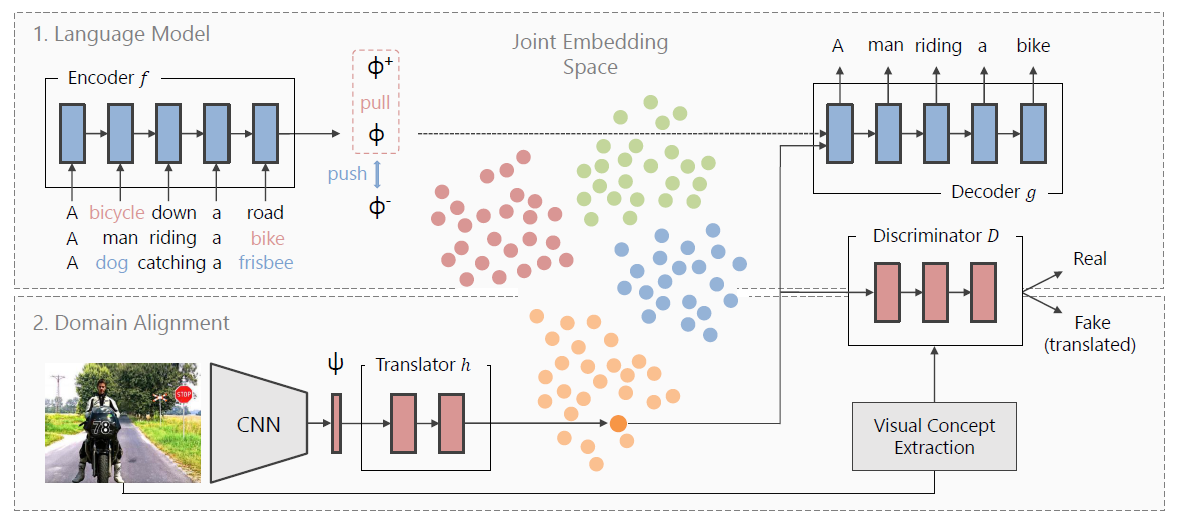
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering [2018]
captioning作为一个图像到文本的跨模态任务,更有效的图像提取特征方式能够提高其指标,该文使用了目标检测网络提取图像特征。
Aligning Linguistic Words and Visual Semantic Units for Image Captioning [2019]
该文在视觉特征提取上更进一步,除了提取object feature,还提取了object之间的关系特征,关于这个关系特征如何提取参考:Neural Motifs: Scene Graph Parsing with Global Context [2017]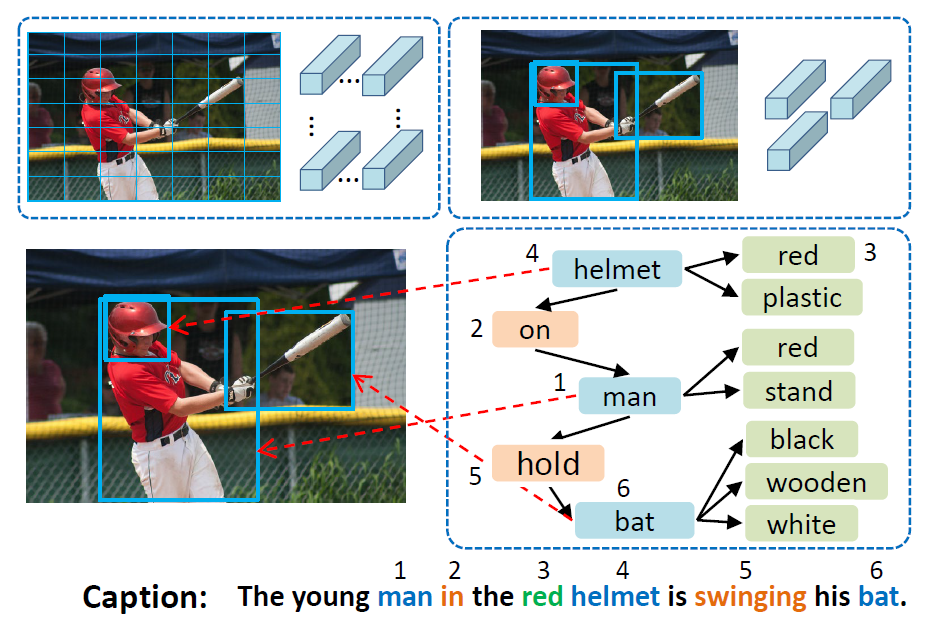
最后其网络框架如图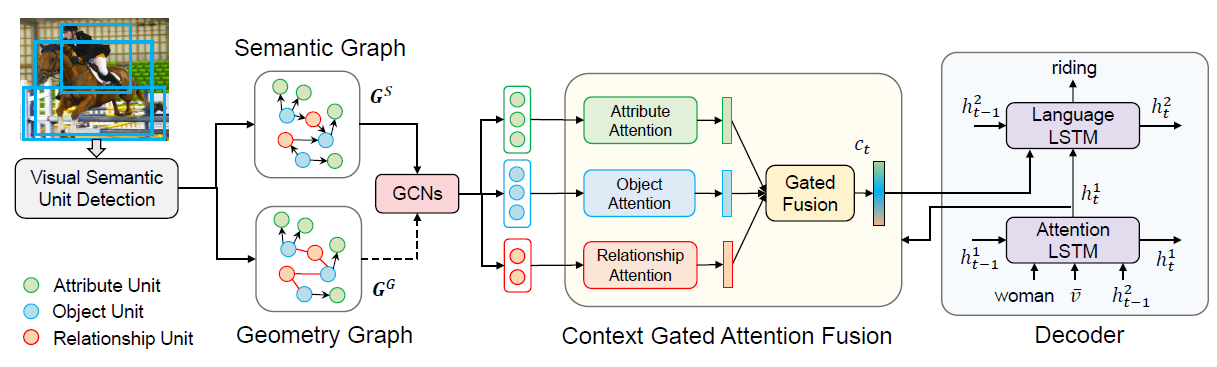
Improving Image Captioning with Better Use of Captions [2020]
在视觉object关系特征提取上,上文用的是Motifs以监督的方式生成的,该文提出从captioning端也构建一个场景图来指导视觉场景图的生成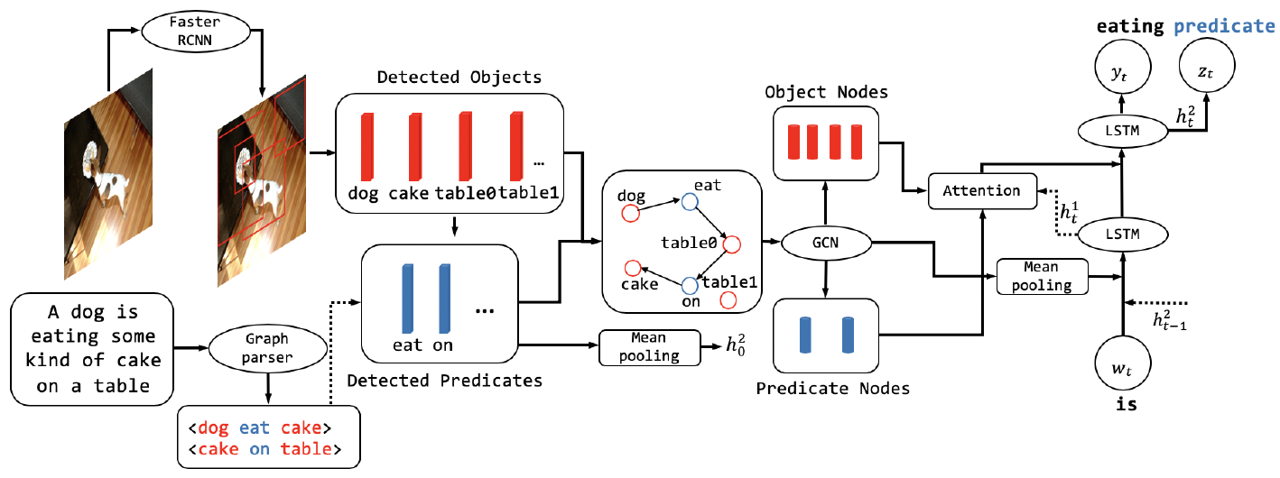
视觉关系应用到基础的检测网络框架也有相关尝试,参见:Visual Commonsense R-CNN [2020]
Object Relational Graph with Teacher-Recommended Learning for Video Captioning [2020]
在image captioning方向可以使用有监督的方式来生成场景图信息,从而利用其中的关系特征,但是在video captioning就难以生成相应的时间和空间关系特征了,该文直接将其包含在网络结构中让其自动学习object之间的关系特征,非常巧妙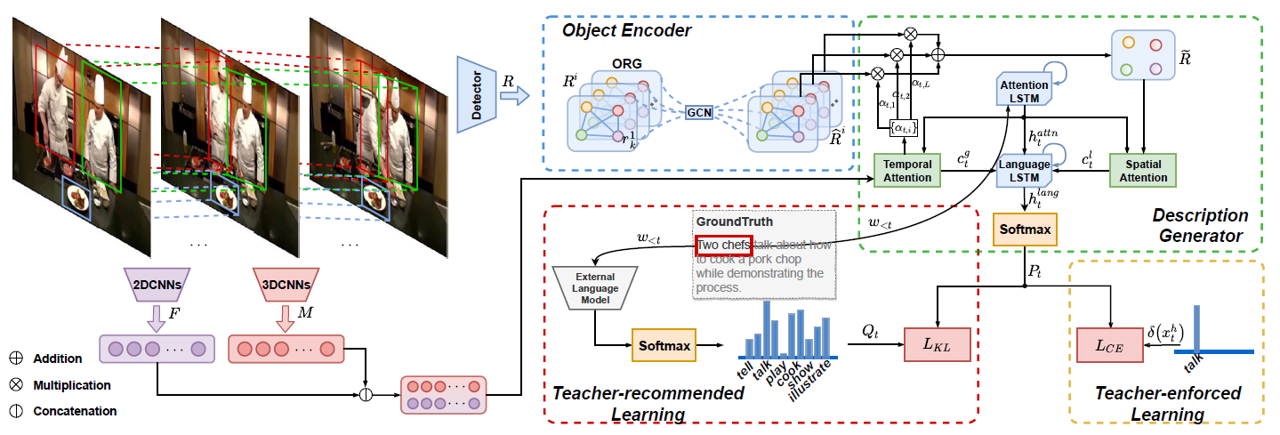
M3: Multimodal Memory Modelling for Video Captioning [2018]
captioning任务作为一个文本生成任务,很多machine translation任务存在的问题及解决方法对captioning任务同样有效,如使用记忆网络来解决长时序依赖问题,对应在machine translation的文章为Neural Turing Machines [2014]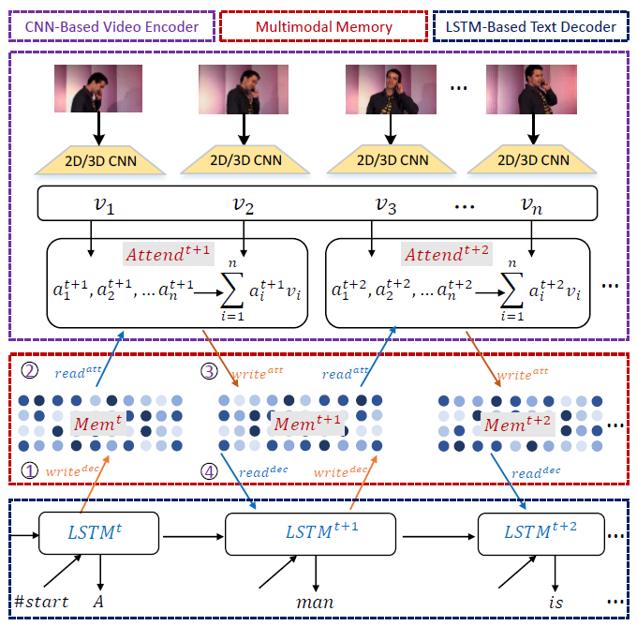
Controllable Video Captioning with POS Sequence Guidance Based on Gated Fusion Network [2019]
或者是使用POS信息来从语法上约束生成的句子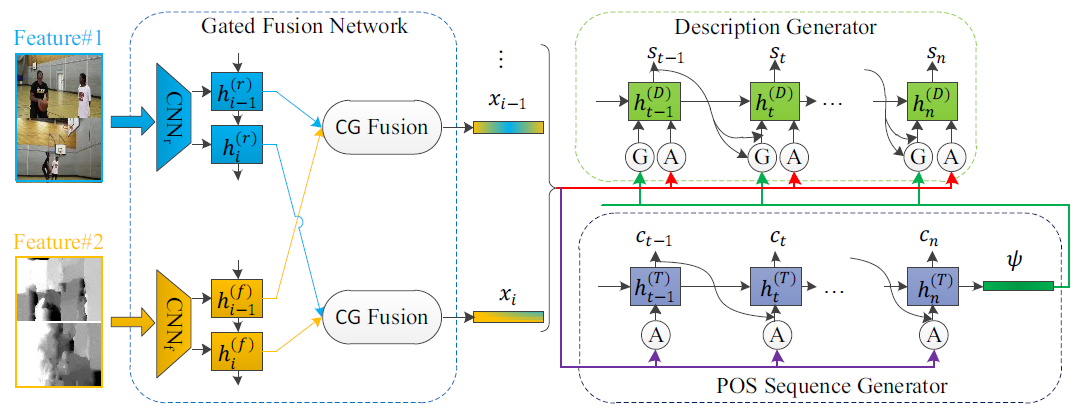
Object Relational Graph with Teacher-Recommended Learning for Video Captioning [2020]
针对语料库的长尾效应,使用预训练模型对其进行修正
Semantic Compositional Networks for Visual Captioning [2017]
从图像信息中提取出属性信息,指导句子的生成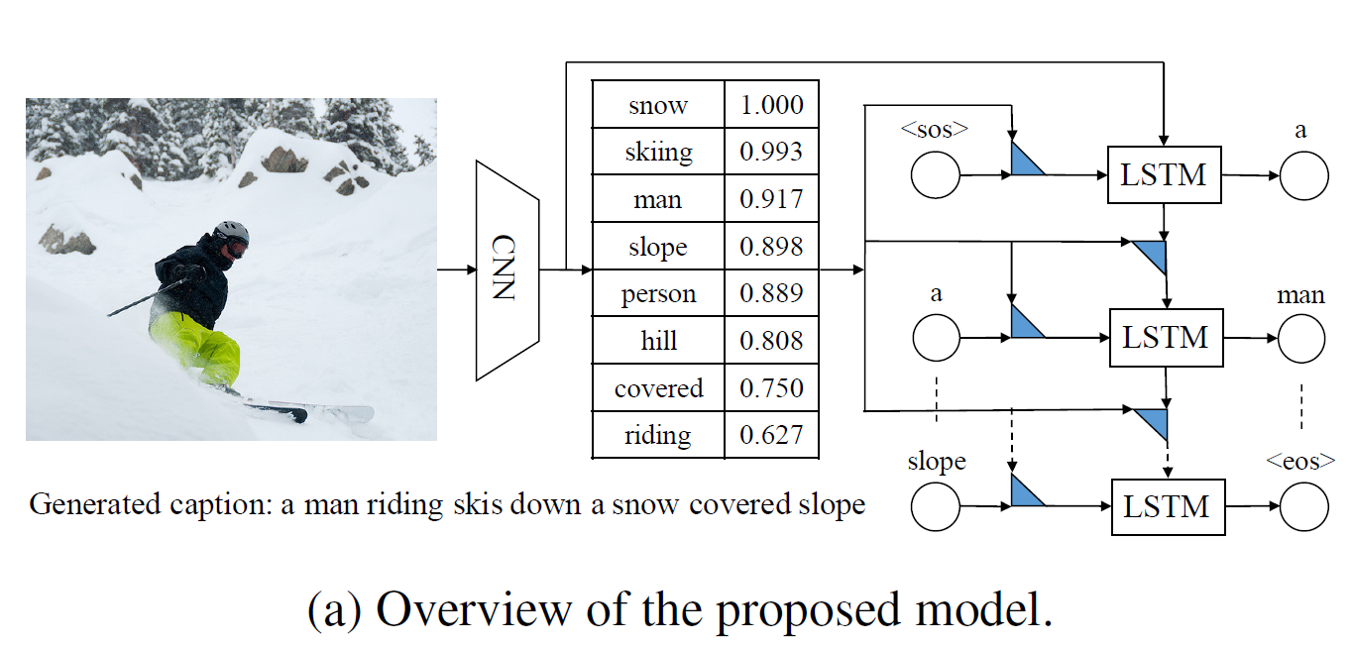
Bridging byWord: Image-Grounded Vocabulary Construction for Visual Captioning [2019]
这篇文章和从图像提取属性信息辅助句子生成类似,不过该文是通过图像来缩小生成句子的词空间,很巧妙。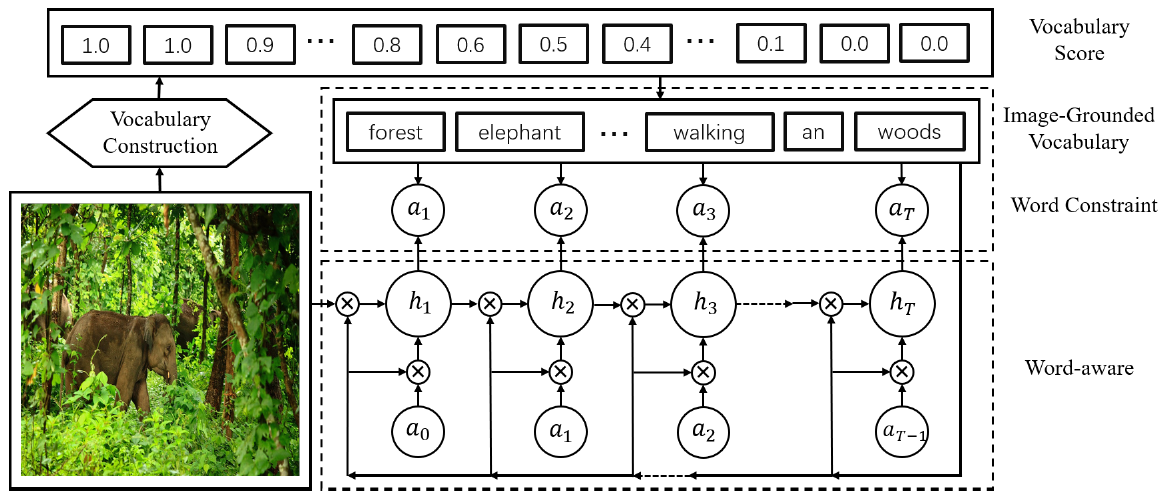
Bridging the Gap between Training and Inference for Neural Machine Translation [2019]
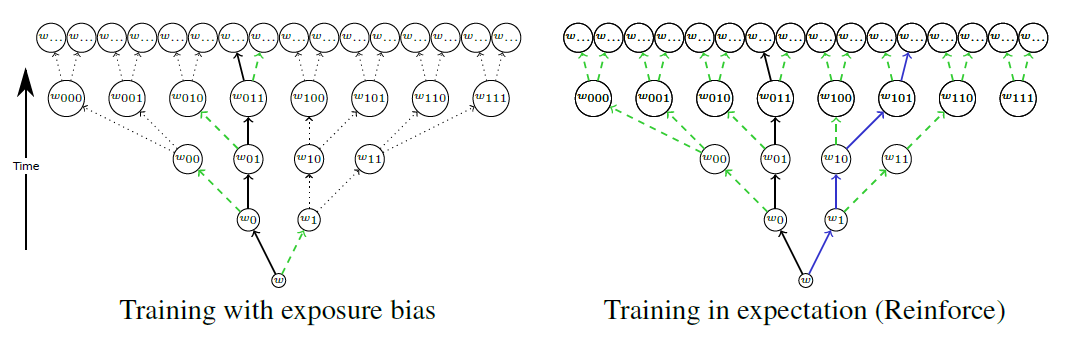
既然是序列生成任务自然存在exposure bias问题,该文在训练与测试的差异及训练难度上取了一个折中(关于训练阶段为什么不直接使用上个一个时间步生成的单词输入到当前时间步,因为这样很难训练好,误差积累太大,难收敛)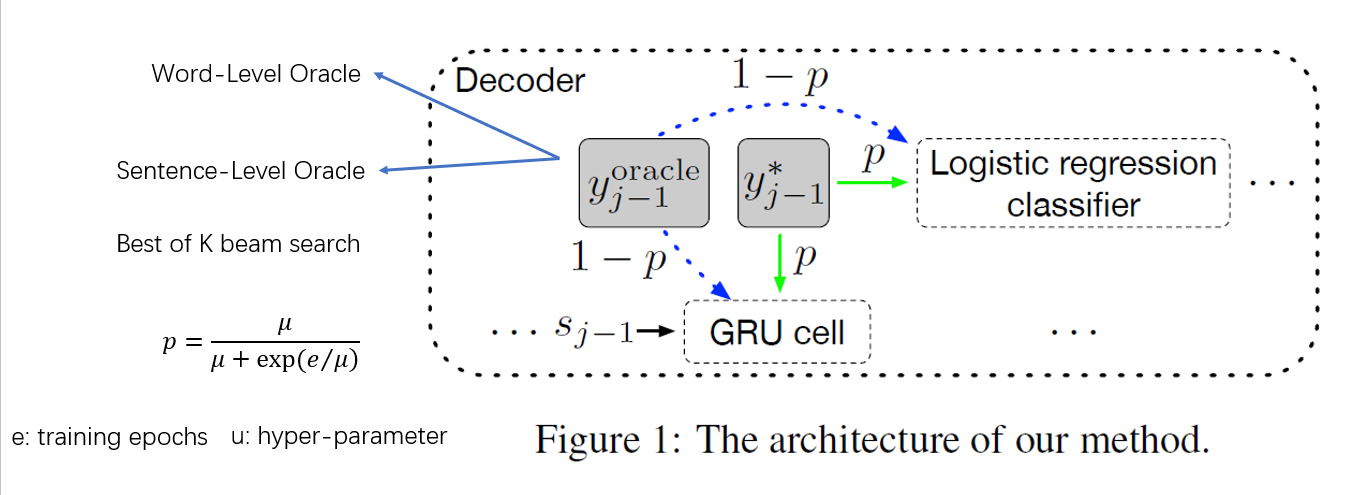
Self-critical Sequence Training for Image Captioning [2017]
其实解决exposure bias问题更有效的方式是使用强化学习,当然一般会先用交叉熵训练好模型,然后交叉熵+强化学习的方式继续训练模型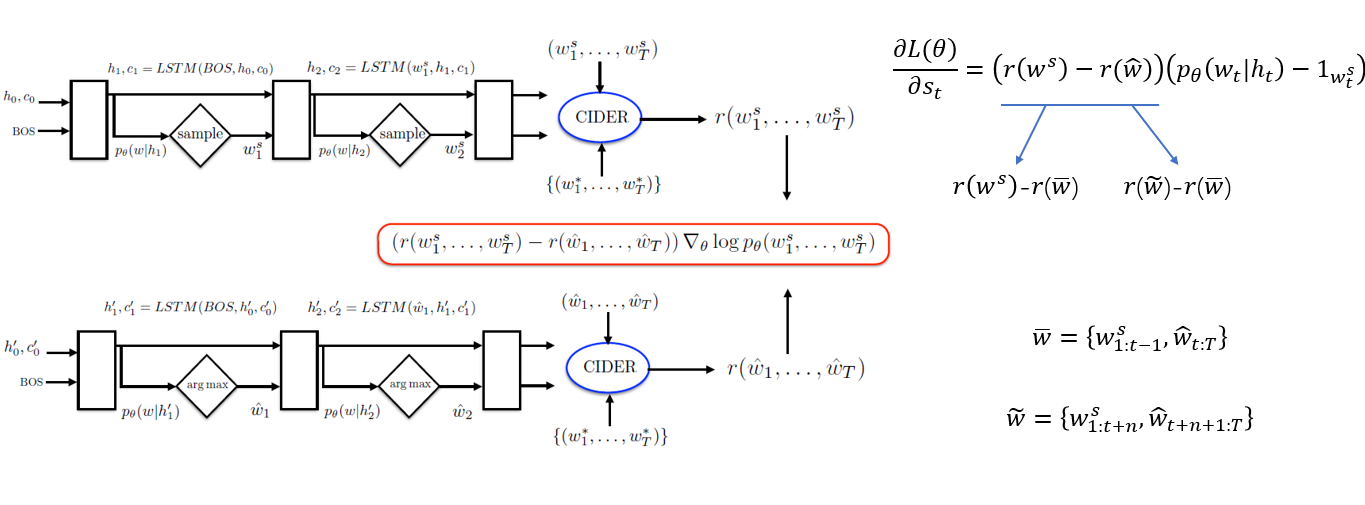
Non-Autoregressive Coarse-to-Fine Video Captioning [2021]
另外也有非自回归这种方式用于生成句子,这种方式自然不存在exposure bias问题,而且生成速度更快,但由于没有直接建模生成单词之间的依赖关系,一般效果不如自回归生成模型,更多需要参考自然语言方向对其的改进。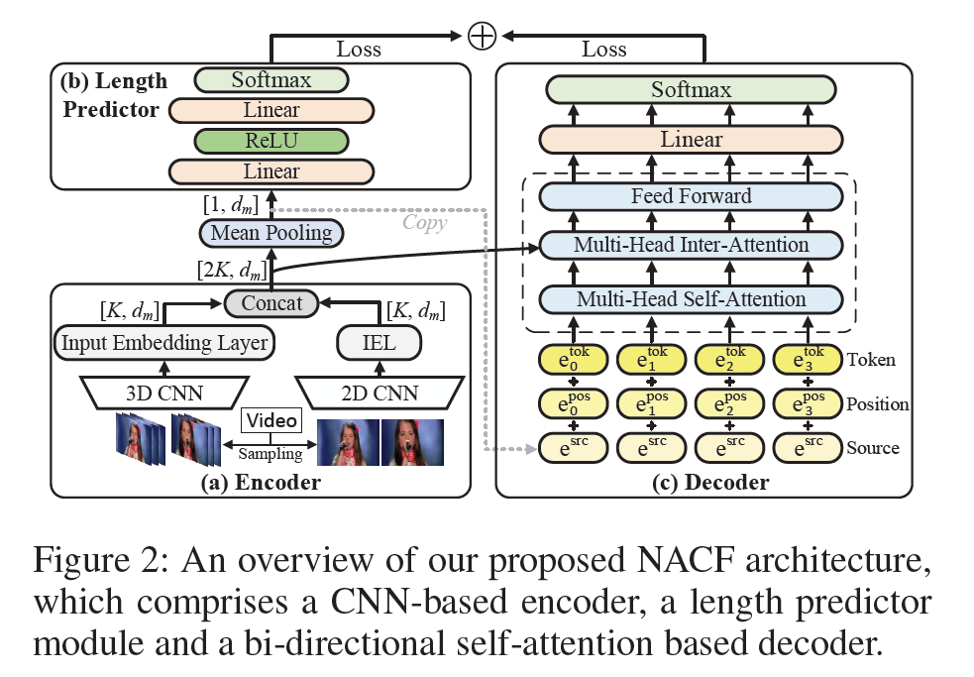
CLIP Meets Video Captioning: Concept-Aware Representation Learning Does Matter[2022]
前文提到了captioning的整个pipeline的第一步是用预训练模型提取图像特征,一般使用的预训练模型都是基于图像分类的,而本文将其换成了CLIP并取得了不错的效果。
CLIP模型来自论文Learning Transferable Visual Models From Natural Language Supervision[2021], 其框架图和主要流程如下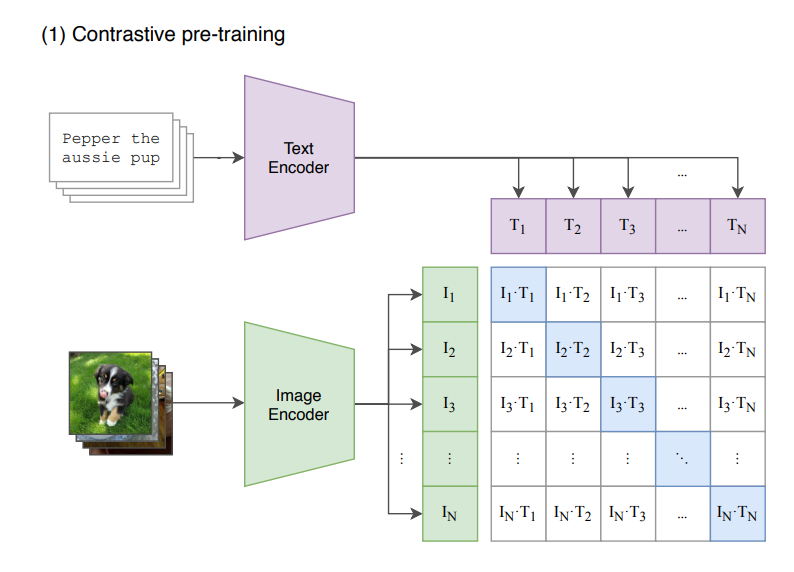
1 | # image_encoder - ResNet or Vision Transformer |
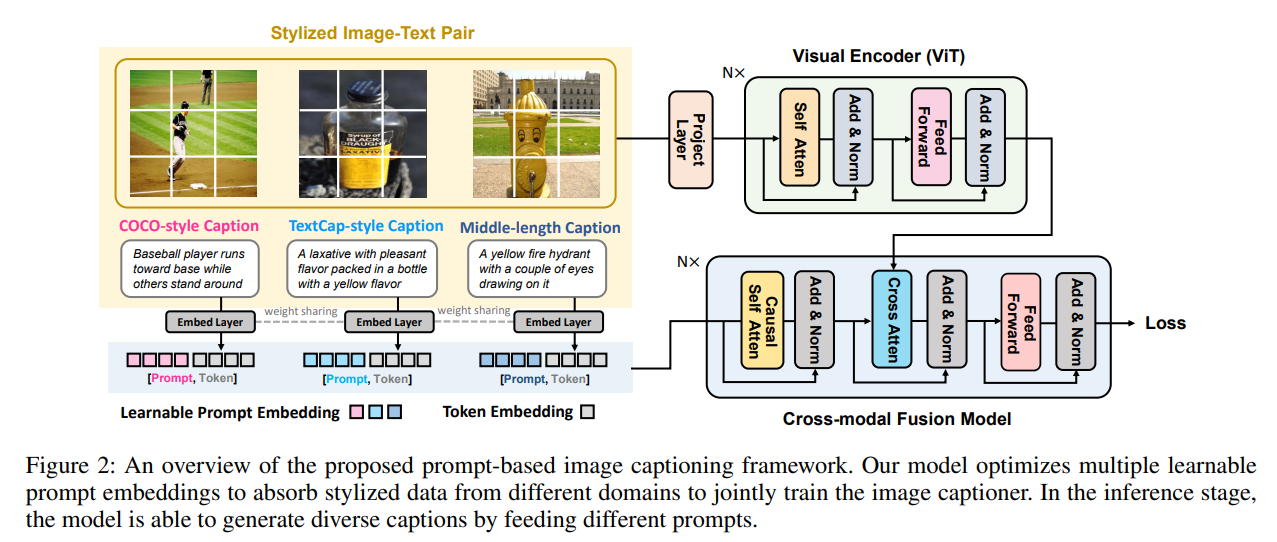
Controllable Image Captioning via Prompting[2022]
该文将Prompt应用到image captioning上, controllable也一直是研究热点,关于prompt知识可以查阅 Pre-train prompt and predict A systematic survey of prompting methods in natural language processing,不过不得不说这些超大规模的预训练模型一般玩不起。