因为参加了一个语义分割相关的项目,对语义分割方向的论文做一个大致的汇总。
Fully Convolutional Networks for Semantic Segmentation[2014]
实现语义分割端到端训练的开山之作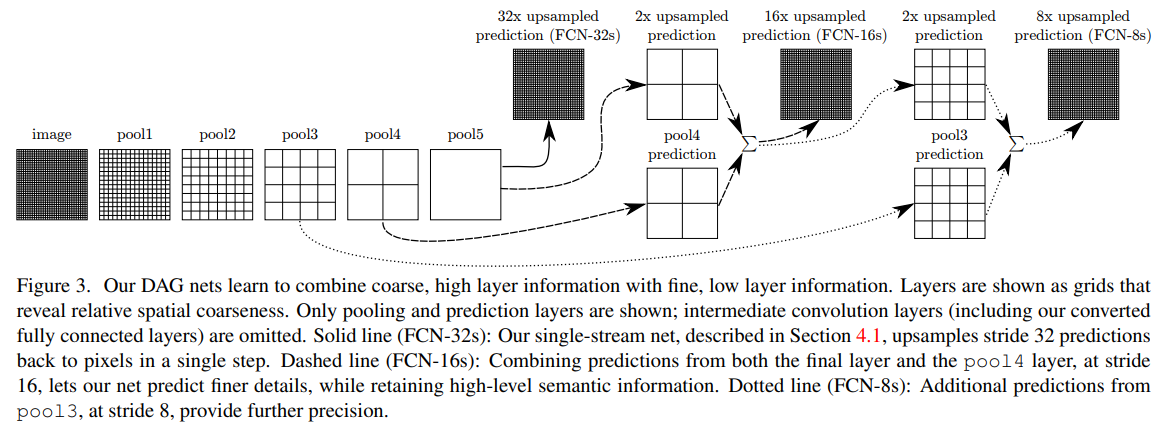
MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS[2015]
使用了空洞卷积,感觉如果是全局上下文比较重要的场景可以试试
PARSENET: LOOKING WIDER TO SEE BETTER[2015]
同样是从全局语义出发,当然文中提到了不同层的语义特征的尺度不同,因此在融合前需要进行归一化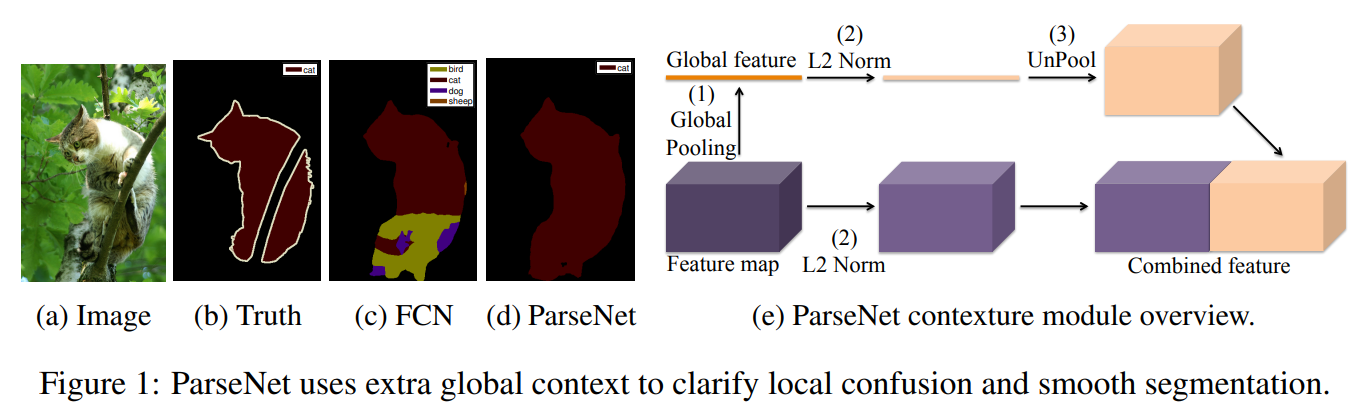
Conditional Random Fields as Recurrent Neural Networks[2016]
将CRF思想融合到卷积中做语义分割的后处理,指标提升了不少,深入研究还有待看代码
Large Kernel Matters —— Improve Semantic Segmentation by Global Convolutional Network[2017]
作者将语义分割分为分类与定位,然后提到分类是受感受野影响的,而设置更大的卷积核是有利于增大感受野的,关于语义分割任务的定位,我引用原文如下
Semantic segmentation can be considered as a per-pixel classification problem. There are two challenges in this task: 1) classification: an object associated to a specific semantic concept should be marked correctly; 2) localization: the classification label for a pixel must be aligned to the appropriate coordinates in output score map. A well-designed segmentation model should deal with the two issues simultaneously.
关于localization,我的理解就是自然规律,常识类信息,比如天空在上面
作者从提升分类效果出发,使用更大的卷积核,框架图如下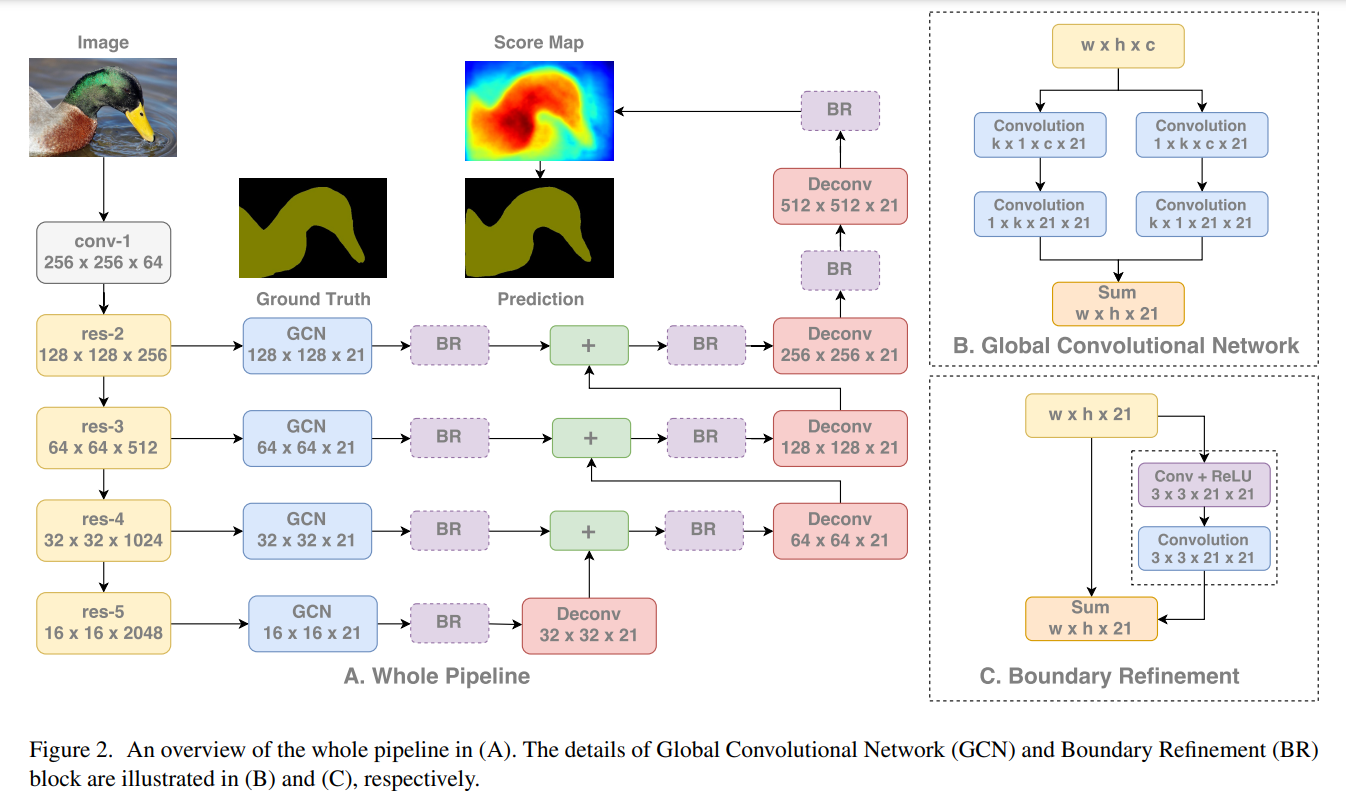
另外作者还展示了一篇研究真实感受野和理论感受野关系的论文,具体paper:OBJECT DETECTORS EMERGE IN DEEP SCENE CNNS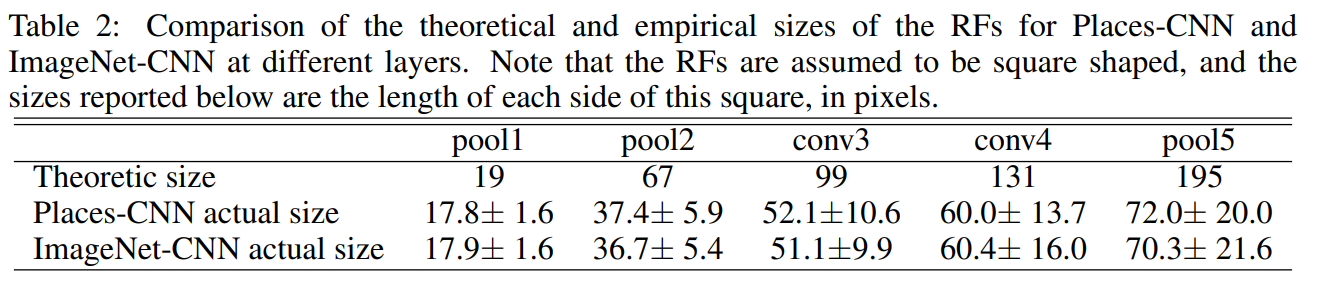
另外作者关于感受野对分类重要性的举例也很有说服力
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation[2017]
整体思路还是利用底层特征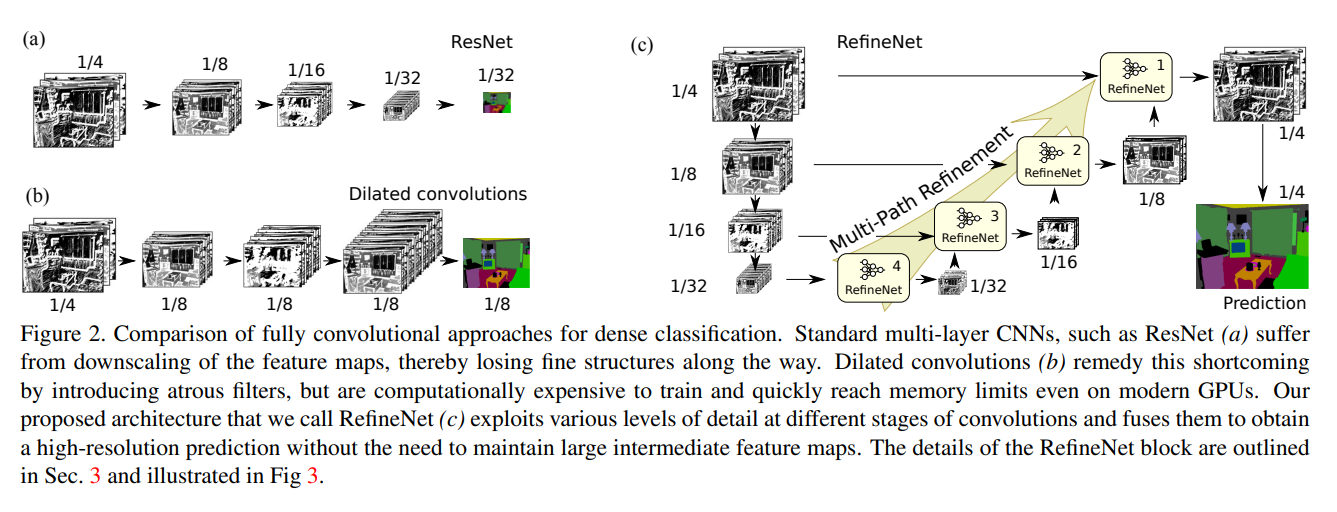
具体框架图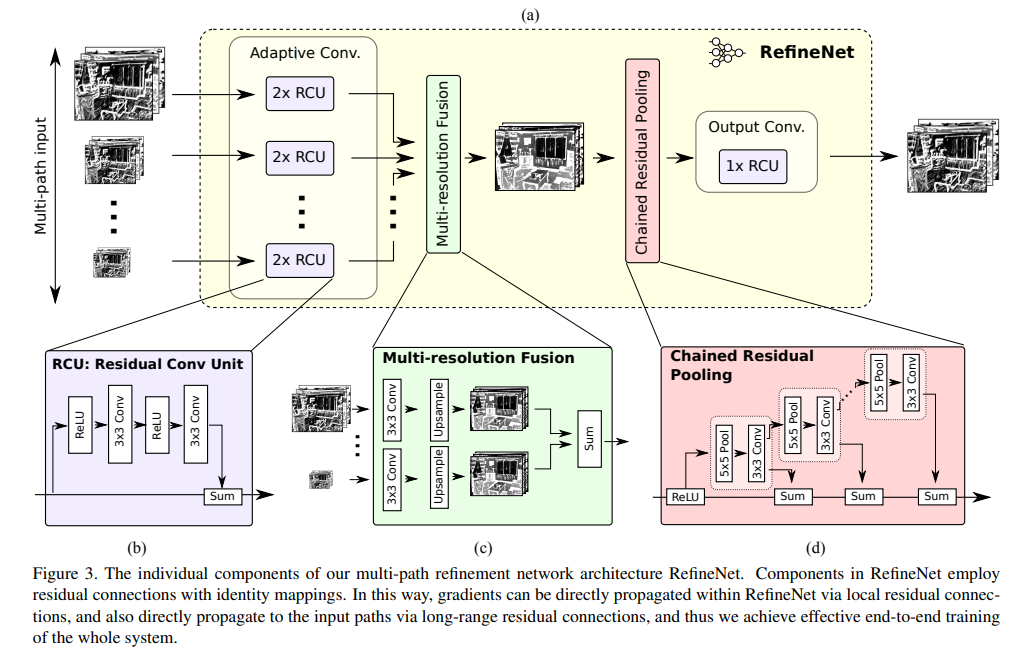
Pyramid Scene Parsing Network[2017]
同样是金字塔的方式利用全局信息及深层次语义信息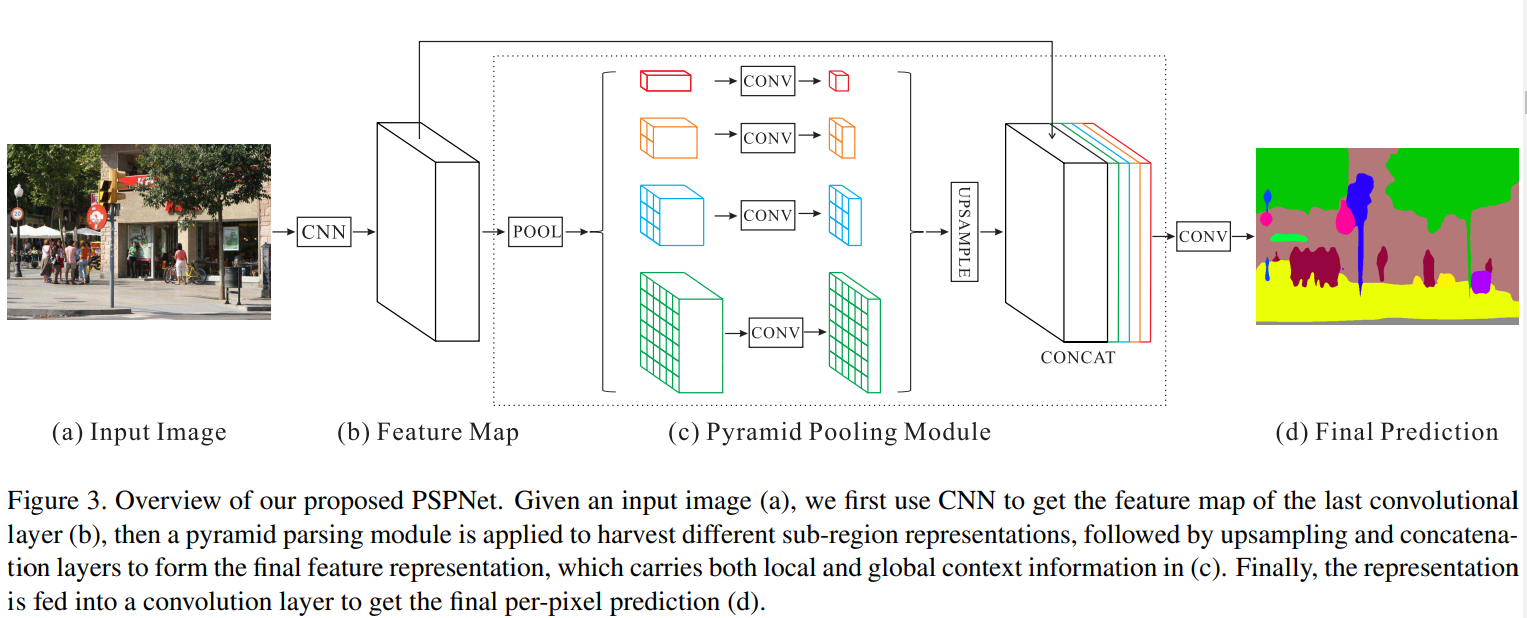
Rethinking Atrous Convolution for Semantic Image Segmentation[2017]
以空洞卷积的方式融合全局信息, 虽然思路和前面的文章大差不差,但本文的related work 做了很详细的总结,值得品读。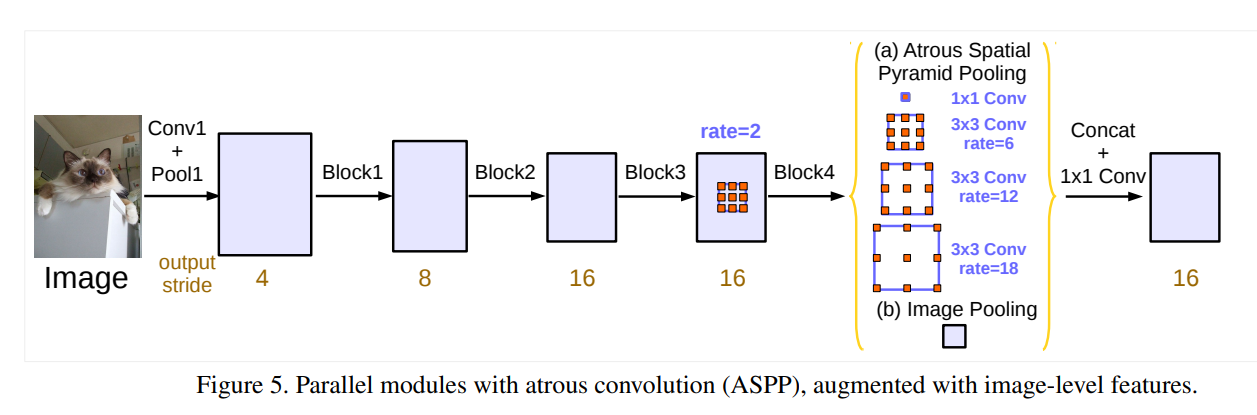
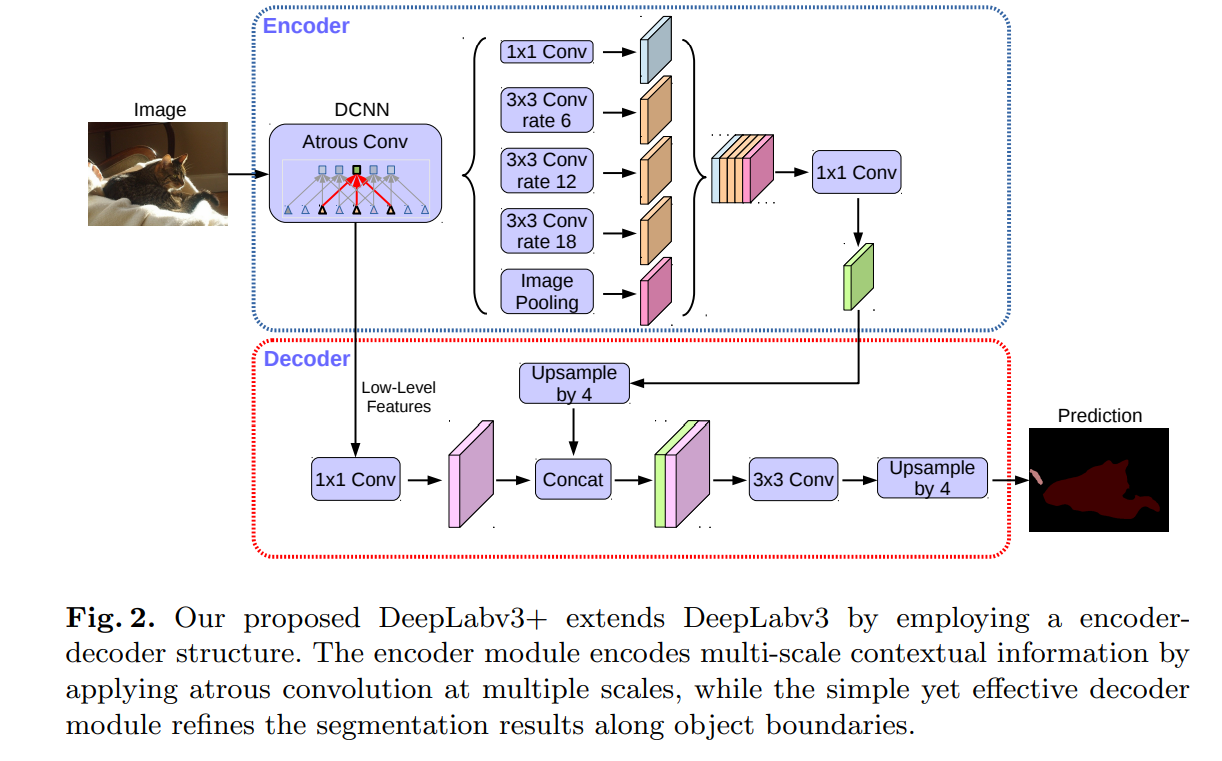
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation[2018]
在deeplab-v3的基础上添加编解码器结构进一步融合底层特征,论文从形状信息来表述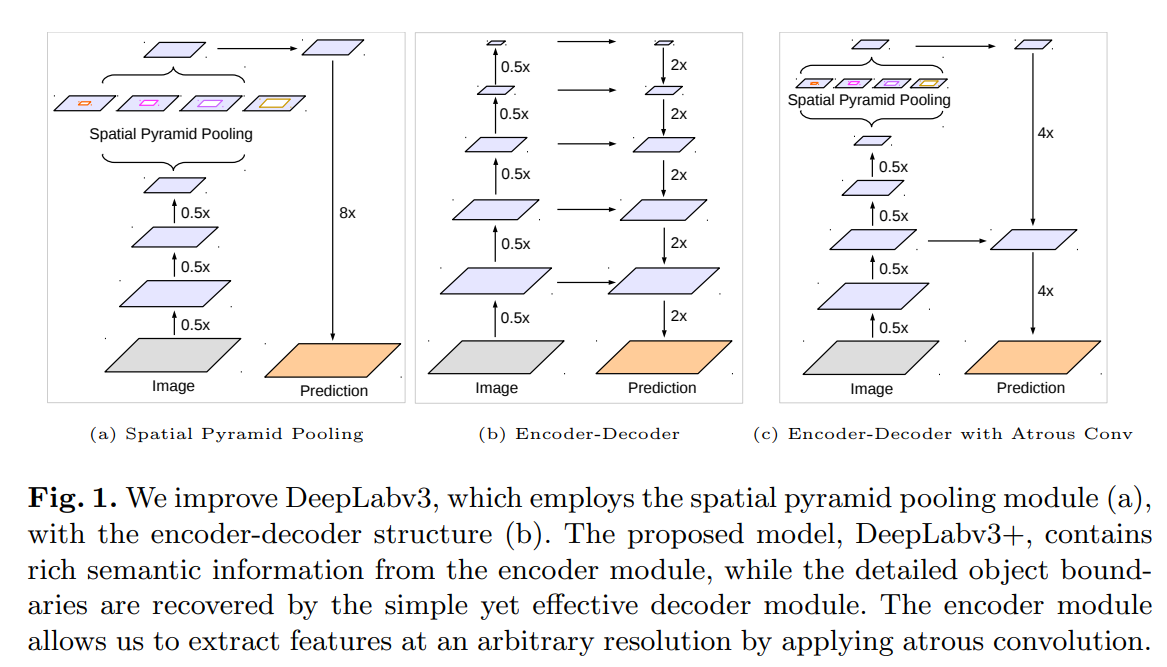
更新中