让机器生成我们想要的图像是一件很酷的事情,本文总结一下图像生成的paper
Generative Adversarial Nets[2014]
对于一般的任务比如图像识别我们有一个确定的类别来训练网络结构,将这成为判别算法。但是有一些情况是没有唯一真实标签的,比如我们只想生成带有数字的图片,至于这个数字是多少,数字写得好不好看不重要,只要是数字就行,也就是符合数字的这样一个特征分布,这时就没法直接用标签来训练网络结构了,于是引入了判别器,用于判断生成的分布是否与目标领域分布相同。
整个训练过程有必要了解
Conditional Generative Adversarial Nets
如果需要生成的不是整个目标图像域的随意一张图片,而是指定类别的图片呢,这时就需要额外添加控制变量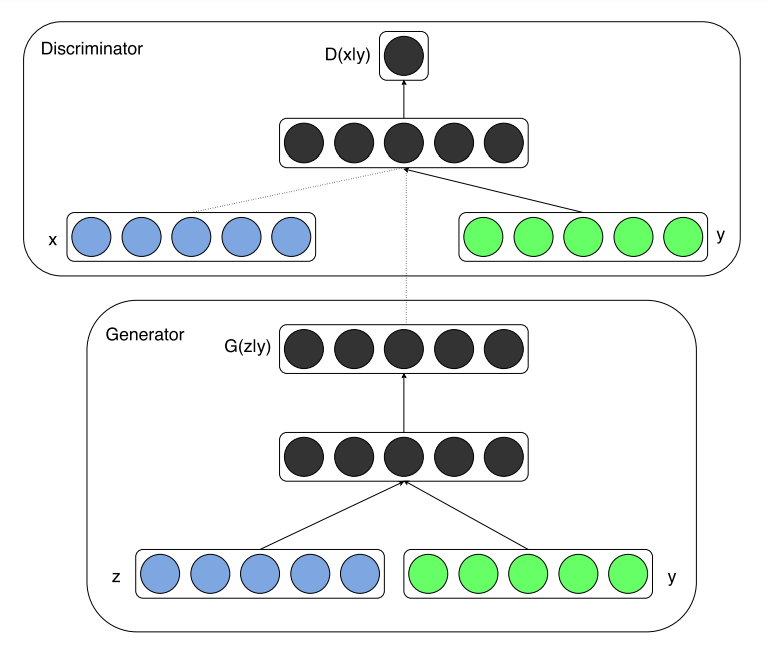
Invertible Conditional GANs for image editing
更进一步,可不可以只改变图像的某些属性,而保留另外一些属性呢,比如给人脸换个发型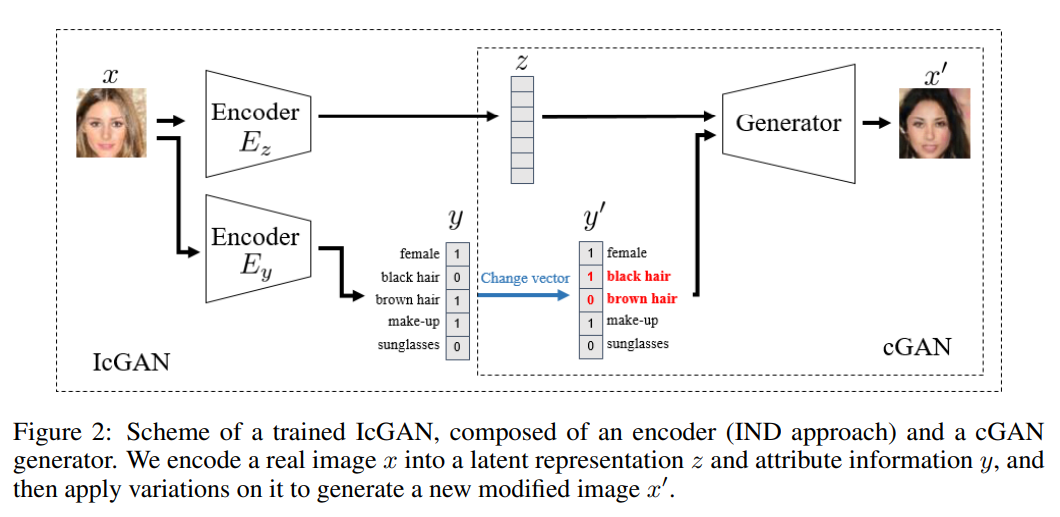
Image-to-Image Translation with Conditional Adversarial Networks
一致性损失函数
$\mathcal{L}{L 1}(G)=\mathbb{E}{x, y, z}\left[|y-G(x, z)|_1\right]$
encoder-decoder改成了u-net结构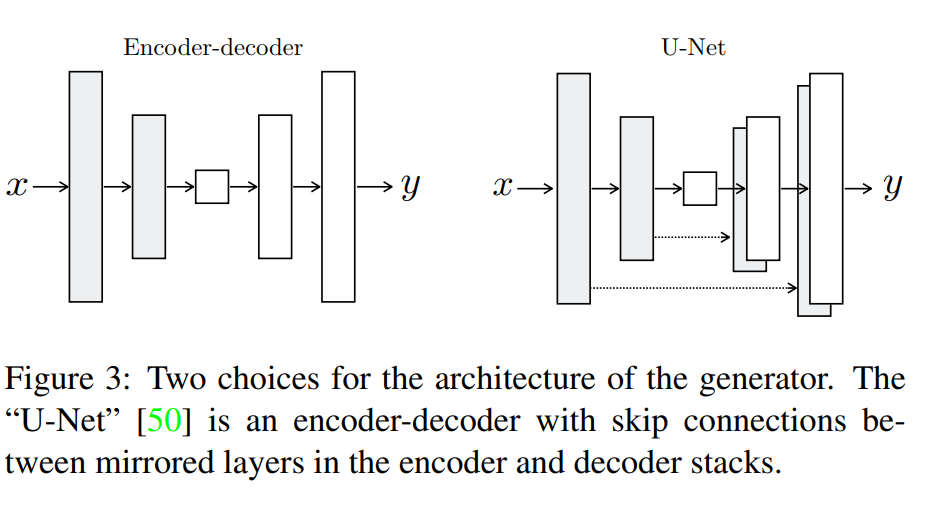
如果只让判别器分别是fake还是real太粗糙了,因此作者提出分块判别:This discriminator tries to classify if each N ×N patch in an image is real or fake.
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
闭环思路,不在需要成对的图像训练网络。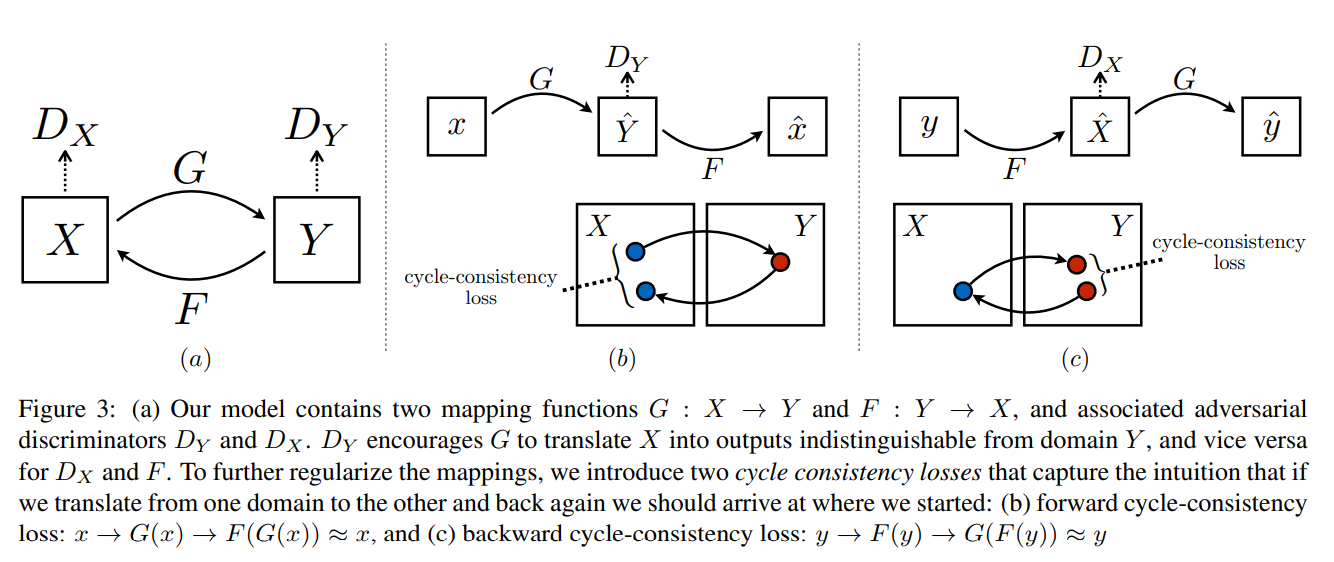
另外需要特别注意的是为了防止 生成器G和生成器F互相包庇,需要引入 identity 损失函数,结合框架图就是 x 经过生成器 F 后生成的图像仍然是 x,而y经过生成器G后生成的图片仍然是y
$\mathcal{L}{\text {identity }}(G, F)=\mathbb{E}{y \sim p_{\text {data }}(y)}\left[|G(y)-y|1\right]+$ $\mathbb{E}{x \sim p_{\text {data }}(x)}\left[|F(x)-x|_1\right]$
更新中