本文介绍如何HLS协议相关知识。
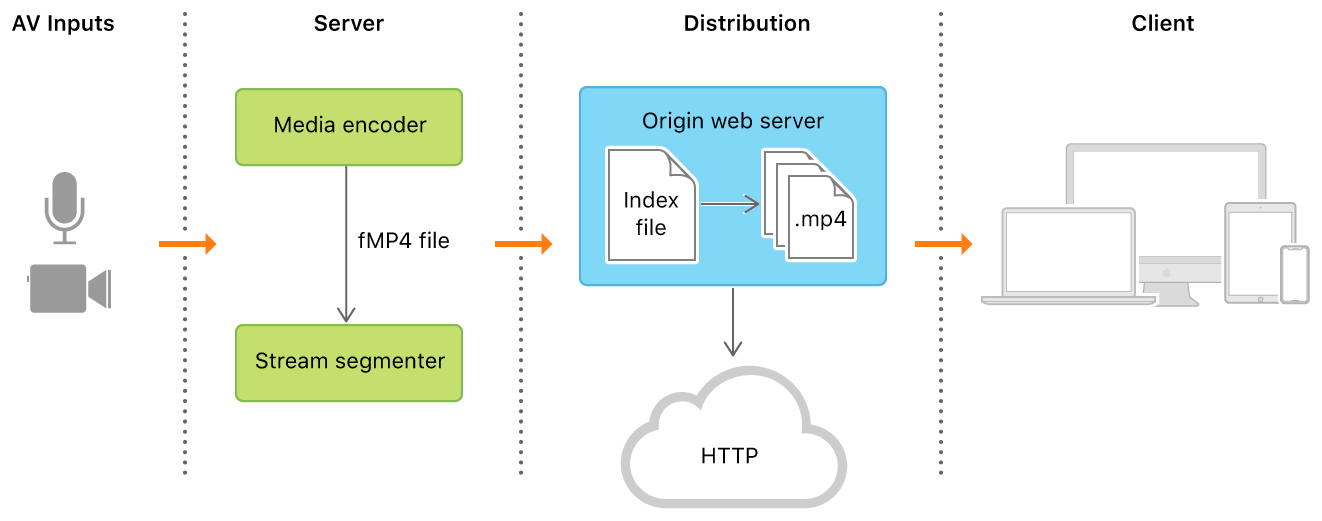
HLS协议 HLS(HTTP Live Streaming)是一种基于http协议的流媒体网络传输协议,很多视频都是通过该协议传输,主要原理就是将视频切分为很多片段,通过一个索引文件m3u8对切分后的视频ts片段进行检索。
关于m3u8中字段的意义如下:
#EXTM3U 指明这是一个m3u8文件
#EXTINF:9.009,http://media.example.com/first.ts 指明片段地址以及片段时长http://media.example.com/second.ts http://media.example.com/third.ts
以下为更详细的字段
#EXTM3U:每个M3U文件第一行必须是这个tag标识。(简单了解)
#EXT-X-VERSION:版本,此属性可用可不用。(简单了解)
#EXT-X-TARGETDURATION:目标持续时间,是用来定义每个TS的【最大】duration(持续时间)。(简单了解)
#EXT-X-ALLOW-CACHE是否允许允许高速缓存。(简单了解)
#EXT-X-MEDIA-SEQUENCE定义当前M3U8文件中第一个文件的序列号,每个ts文件在M3U8文件中都有固定唯一的序列号。(简单了解)
#EXT-X-DISCONTINUITY:播放器重新初始化(简单了解)
#EXT-X-KEY定义加密方式,用来加密的密钥文件key的URL,加密方法(例如AES-128),以及IV加密向量。(记住)
#EXTINF:指定每个媒体段(ts文件)的持续时间,这个仅对其后面的TS链接有效,每两个媒体段(ts文件)间被这个tag分隔开。(简单了解)
#EXT-X-ENDLIST表明M3U8文件的结束。(简单了解)
python实现基于HLS的流媒体文件获取 由HLS协议的原理可知,解析HLS文件先要找到m3u8索引文件,然后获取视频片段进行拼接。
示例一 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 import requestsfrom urllib.parse import urljoinimport reimport osimport asyncioimport aiohttpfrom Crypto.Cipher import AESdirName = 'tsLib' if not os.path.exists(dirName): os.mkdir(dirName) headers = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36' } m1_url = 'https://v4.cdtlas.com/20220311/xEaAxRVd/index.m3u8' m1_page_text = requests.get(url=m1_url,headers=headers).text m1_page_text = m1_page_text.strip() m2_url = '' for line in m1_page_text.split('\n' ): if not line.startswith('#' ): m2_url = line m2_url = urljoin(m1_url,m2_url) m2_page_text = requests.get(url=m2_url,headers=headers).text m2_page_text = m2_page_text.strip() key_url = re.findall('URI="(.*?)"' ,m2_page_text,re.S)[0 ] key_url =urljoin(m1_url,key_url) key = requests.get(url=key_url,headers=headers).content iv = b'0000000000000000' ts_url_list = [] for line in m2_page_text.split('\n' ): if not line.startswith("#" ): ts_url = line ts_url = urljoin(m1_url,ts_url) ts_url_list.append(ts_url) async def get_ts (url ): async with aiohttp.ClientSession() as sess: async with await sess.get(url=url,headers=headers) as response: ts_data = await response.read() aes = AES.new(key=key, mode=AES.MODE_CBC, iv=iv) desc_data = aes.decrypt(ts_data) return [desc_data,url] def download (t ): r_list = t.result() data =r_list[0 ] url = r_list[1 ] ts_name = url.split('/' )[-1 ] ts_path = dirName + '/' + ts_name with open (ts_path, 'wb' ) as fp: fp.write(data) print (ts_name, '下载保存成功!' ) tasks = [] for url in ts_url_list: c = get_ts(url) task = asyncio.ensure_future(c) task.add_done_callback(download) tasks.append(task) loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks))
示例二 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import requestsimport osfrom Crypto.Cipher import AESimport timeheaders = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36 Edg/86.0.622.56" , "Connection" : "close" } def m3u8 (url,movie_name ): base_url = url[:url.rfind('/' )+1 ] rs = requests.get(url,headers=headers).text list_content = rs.split('\n' ) player_list = [] if not os.path.exists('{}' .format (movie_name)): os.mkdir('{}' .format (movie_name)) key = '' for index,line in enumerate (list_content): if "#EXT-X-KEY" in line: method_pos = line.find("METHOD" ) comma_pos = line.find("," ) method = line[method_pos:comma_pos].split('=' )[1 ] print ("Decode Method:" , method) uri_pos = line.find("URI" ) quotation_mark_pos = line.rfind('"' ) key_path = line[uri_pos:quotation_mark_pos].split('"' )[1 ] key_url = key_path res = requests.get(key_url,headers=headers) key = res.content """ 获取.ts文件链接地址方式可根据需要进行定制 """ if '#EXTINF' in line: if 'http' in list_content[index + 1 ]: href = list_content[index + 1 ] player_list.append(href) else : href = base_url + list_content[index+1 ] player_list.append(href) if (len (key)): print ('此视频经过加密' ) for i,j in enumerate (player_list): if not os.path.exists('{}/' .format (movie_name + str (i+1 ) + '.ts' )): cryptor = AES.new(key, AES.MODE_CBC, key) res = requests.get(j,headers=headers) requests.adapters.DEFAULT_RETRIES = 5 with open ('{}/' .format (movie_name) + str (i+1 ) + '.ts' ,'wb' ) as file: file.write(cryptor.decrypt(res.content)) print ('正在写入第{}个文件' .format (i+1 )) else : pass else : print ('此视频未加密' ) for i,j in enumerate (player_list): if not os.path.exists('{}/' .format (movie_name + str (i+1 ) + '.ts' )): res = requests.get(j,headers=headers) with open ('{}/' .format (movie_name) + str (i+1 ) + '.ts' ,'wb' ) as file: file.write(res.content) print ('正在写入第{}个文件' .format (i+1 )) print ('下载完成' ) name = 'nz' url = "https://vod3.buycar5.cn/20210402/Z4mMbiNW/1000kb/hls/index.m3u8" m3u8(url,name)
示例三 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import timeimport m3u8import requestsheaders = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36" } def get_live_url (cid, platform='h5' ): playUrl = 'https://api.live.bilibili.com/xlive/web-room/v1/playUrl/playUrl' params = { 'cid' : cid, 'qn' : 150 , 'platform' : platform, 'ptype' : 16 } response = requests.get(playUrl, headers=headers, params=params).json() text = response['data' ]['durl' ] url = text[-1 ]['url' ] return url def get_real_url (url ): playlist = m3u8.load(uri=url, headers=headers) return playlist.playlists[0 ].absolute_uri def download_video (url, max_count=1000 , max_size=120 *1024 *1024 ): max_id = None size = 0 for i in range (1 , max_count+1 ): playlist = m3u8.load(uri=url, headers=headers) for seg in playlist.segments: current_id = int (seg.uri[1 :seg.uri.find("." )]) if max_id and current_id <= max_id: continue with open ("combine.mp4" , "ab" if max_id else "wb" ) as f: r = requests.get(seg.absolute_uri, headers=headers) data = r.content size += len (data) f.write(data) print ( f"\r下载次数({i} /{max_count} ),已下载:{size/1024 /1024 :.2 f} MB" , end="" ) if size >= max_size: print ("\n文件已经超过大小限制,下载结束!" ) return max_id = current_id time.sleep(2 ) url = get_live_url('22273117' ) real_url = get_real_url(url) download_video(real_url)
示例四 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 from time import timeimport m3u8import requestsfrom threading import Threadcheck = [] a = 0 stop = False Vname = input ("Video name :" ) url = input ("Enter the m3u8 link of the resolution that you want:" ) while True : try : r = requests.get(url) m3u8_master = m3u8.loads(r.text) m3u8_master.data['playlists' ][-1 ]['uri' ] url = input ( "\nIt may be the master m3u8 link. Enter link of indivisual resolution which you want :\n" ) continue except : pass try : r = requests.get(url) Playlist = m3u8.loads(r.text) tsfile = Playlist.data['segments' ] if tsfile == []: url = input ("\nEnter correct Link :" ) continue break except : url = input ("\nEnter correct Link :" ) print ("\nPress Enter to STOP\n" )def downLink (): global a, run start = time() while True : global stop if stop: print ("\nSTOP" ) break r = requests.get(url) Playlist = m3u8.loads(r.text) tsfile = Playlist.data['segments' ] for link in tsfile: if link["uri" ] not in check: check.append(link["uri" ]) a += 1 print (time() - start, end="\r" ) if time() - start > 3000 : run = False break def download (): global a, stop b = 0 run = True with open (Vname + ".ts" , "wb" ) as f: while run: if a > b: p = requests.get(check[b]) f.write(p.content) b += 1 if stop: f.close() break def STOP (): global stop input () stop = True s1 = Thread(target=downLink) s2 = Thread(target=download) s3 = Thread(target=STOP) s1.start() s2.start() s3.start()
对于实时视频流原理是一样的,只是需要循环请求m3u8文件获取ts片段路径,另外如果加密就利用Crypto.Cipher包进行解密,解密的输入包括key和iv。