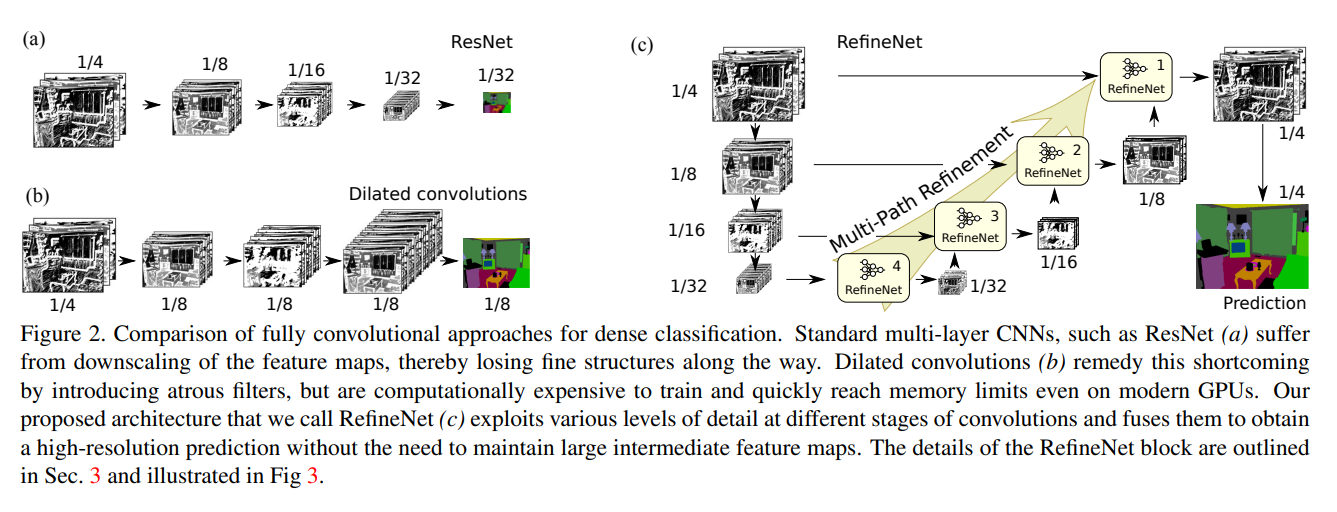
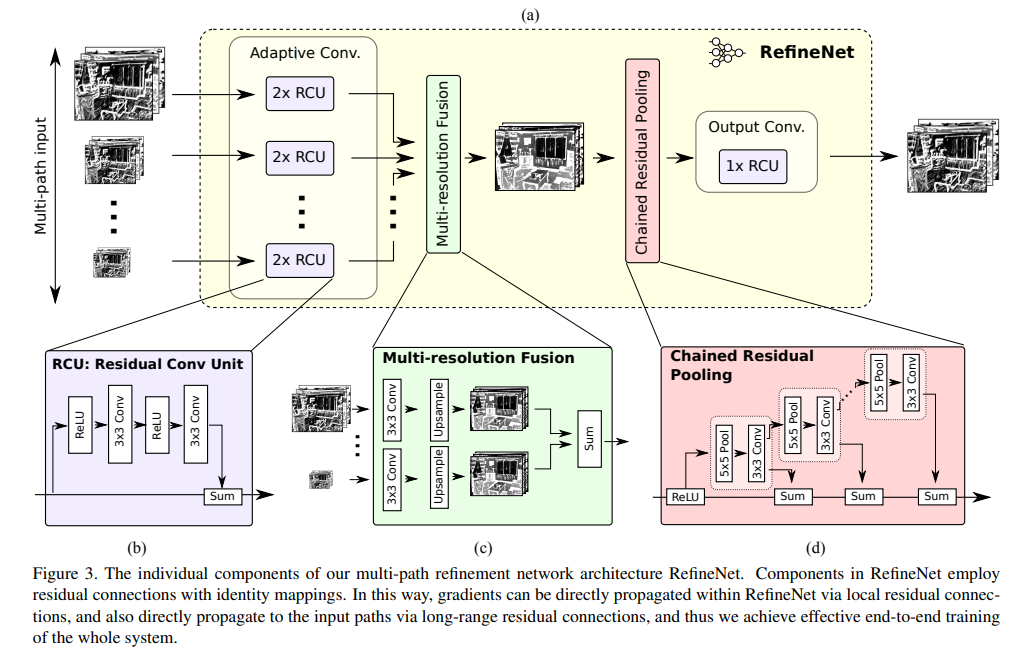
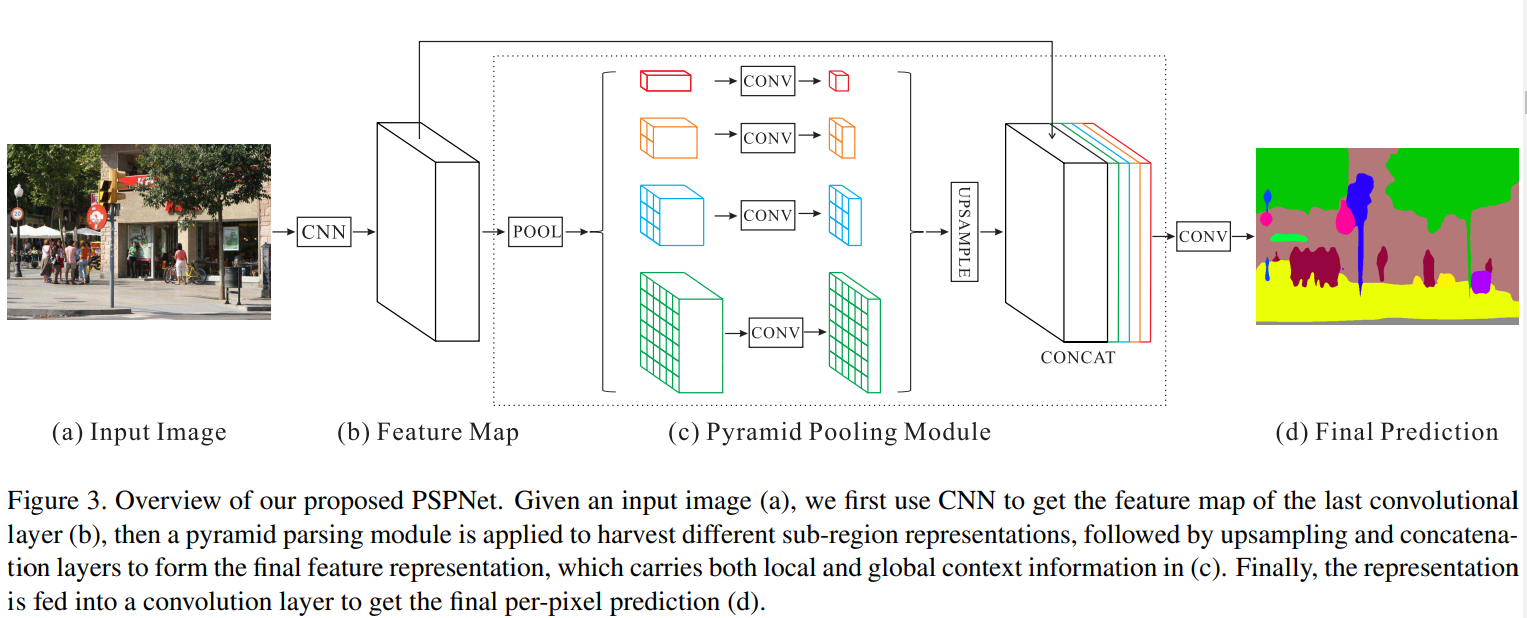
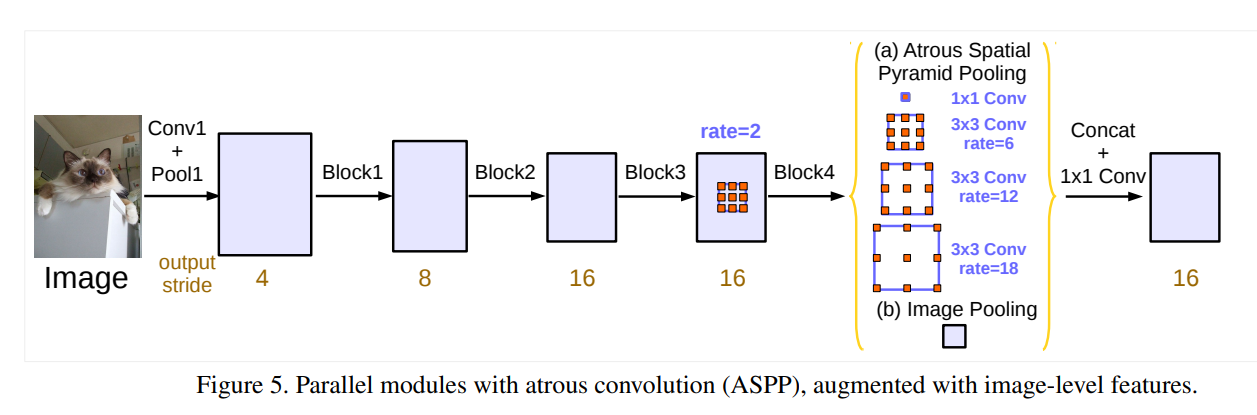
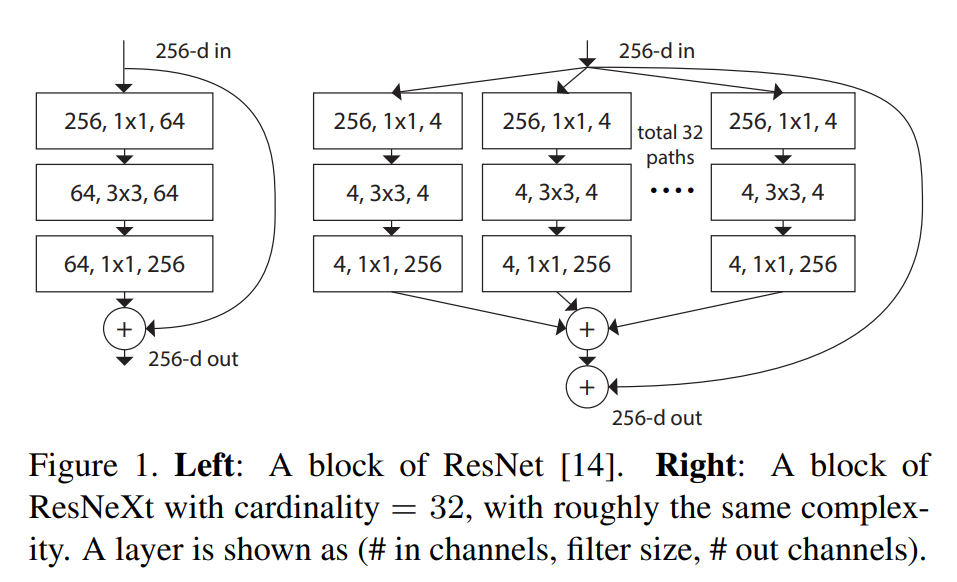
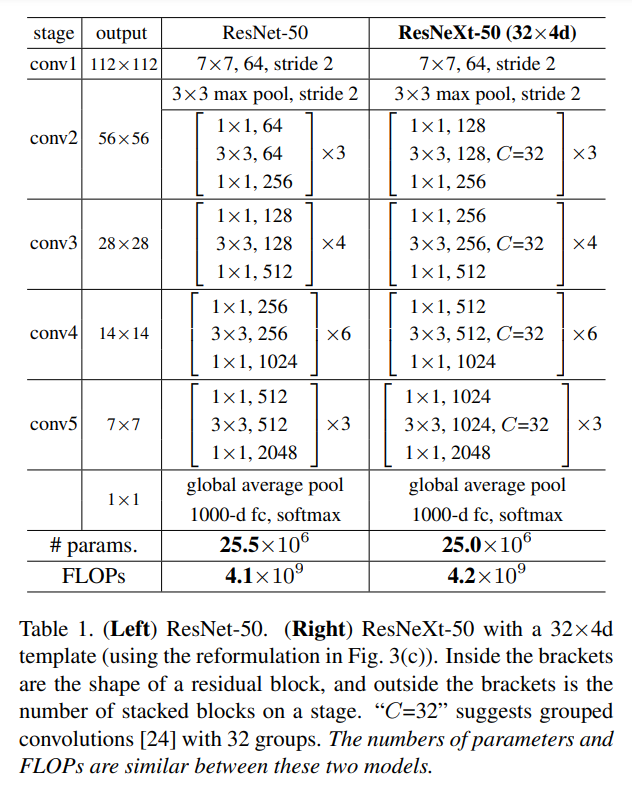
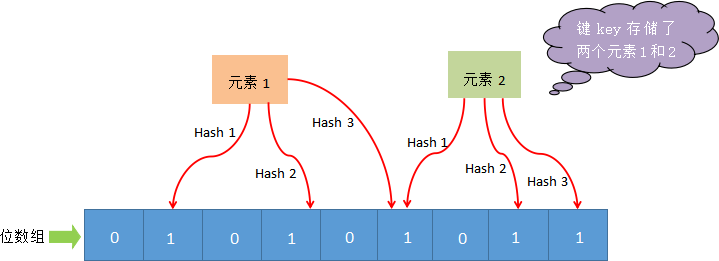
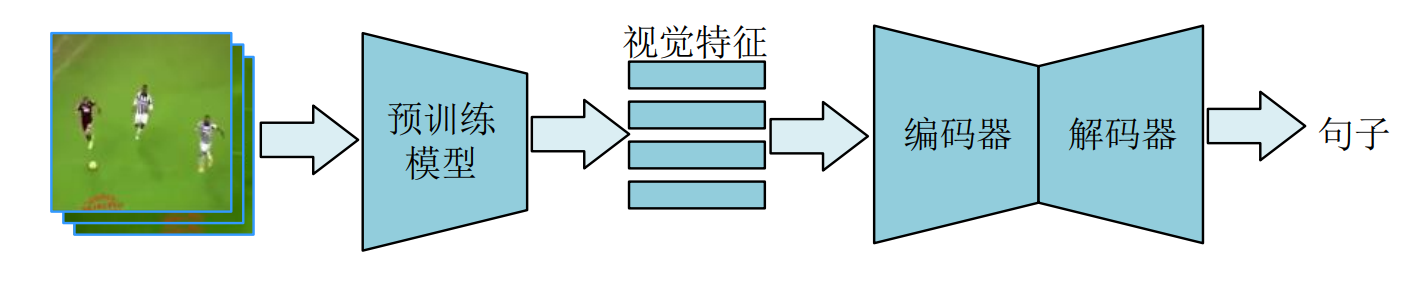
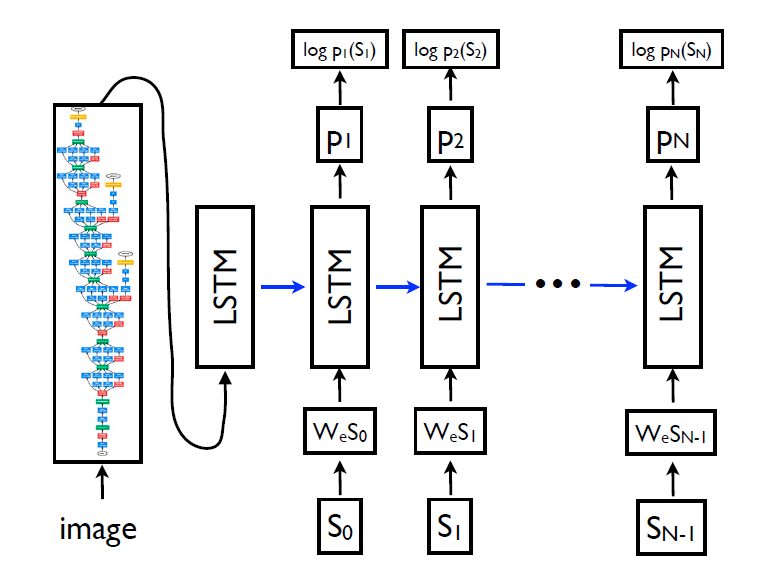
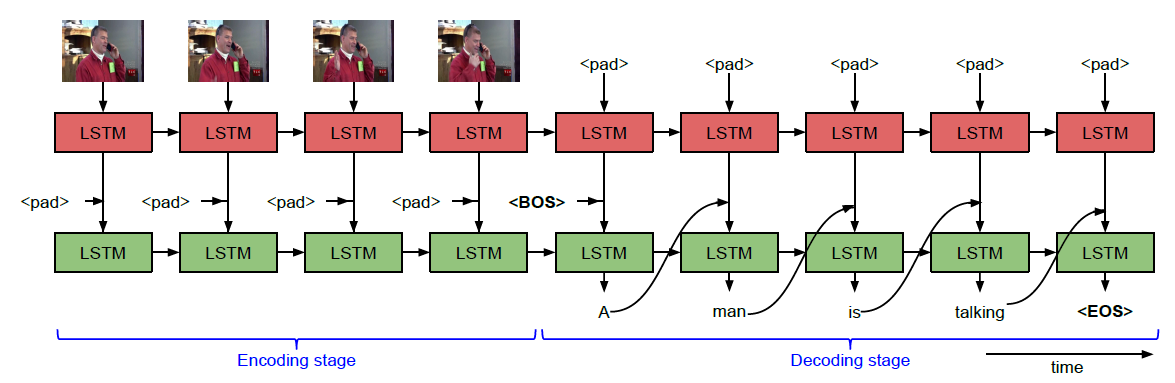
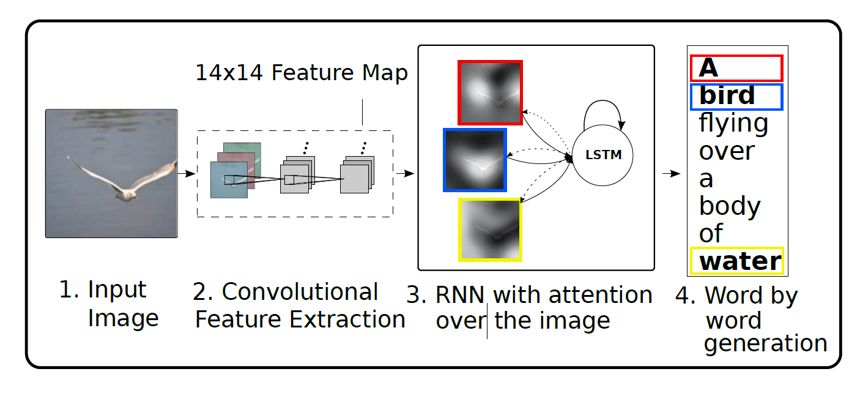
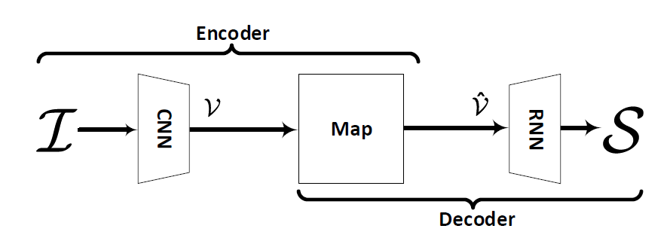
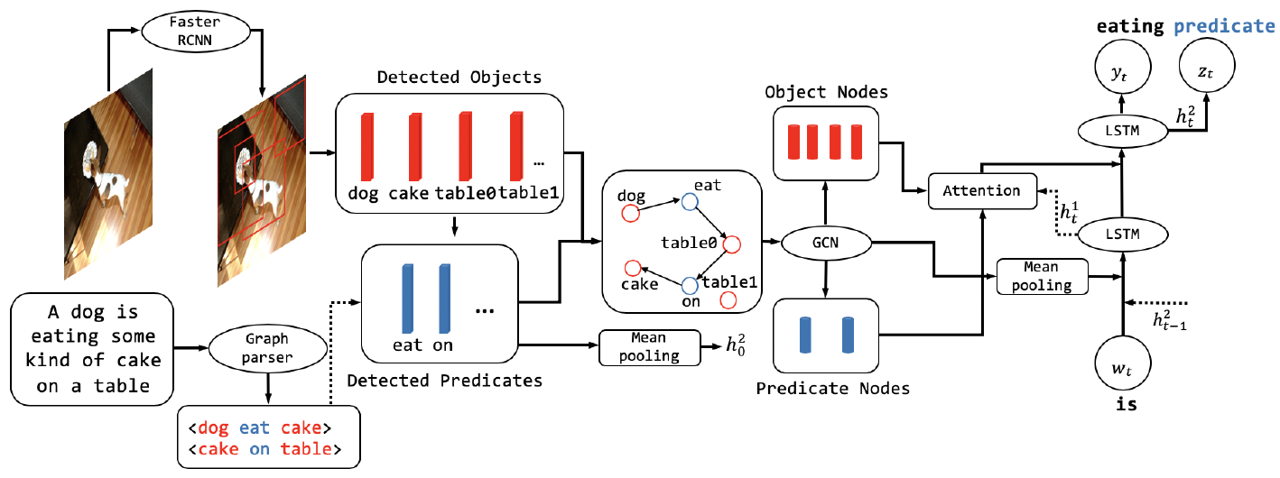
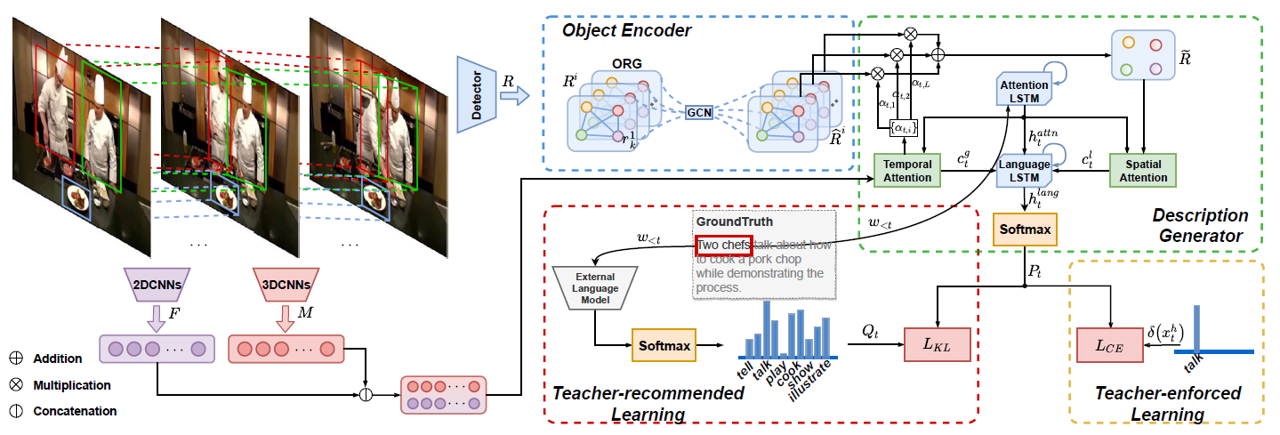
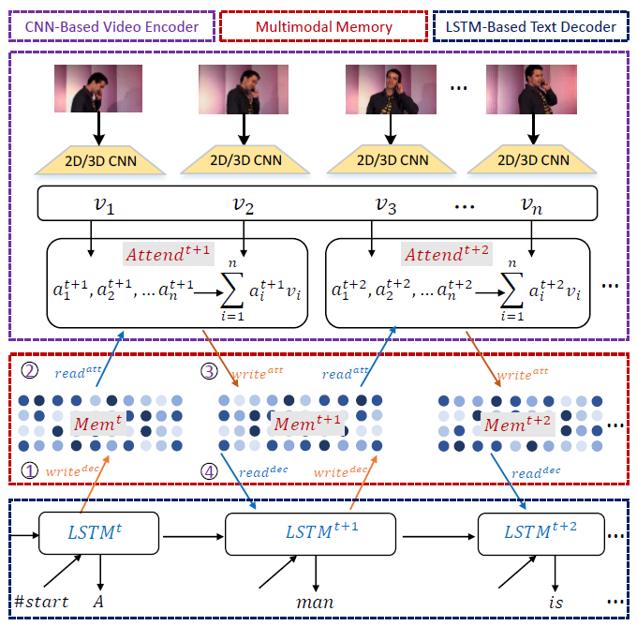
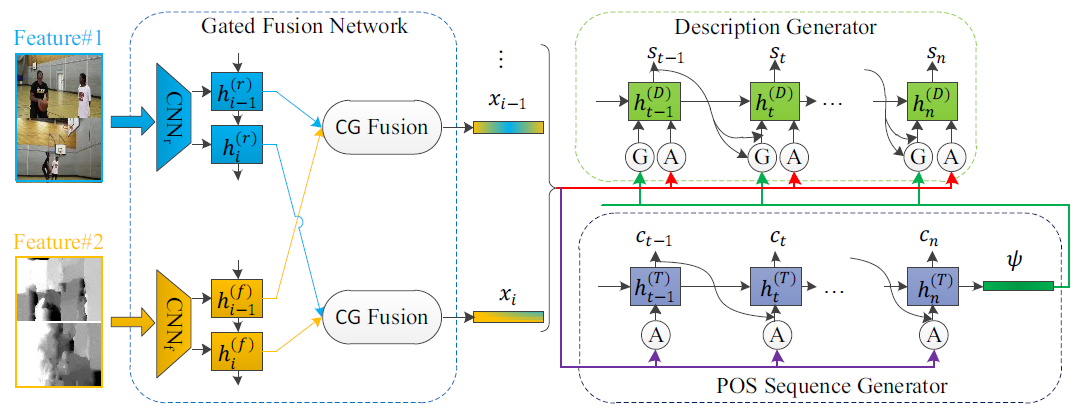
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
| import random
import aiohttp
import asyncio
from bs4 import BeautifulSoup as bs
import re
from urllib import parse
import os
import time
import requests
import redis
from hashlib import md5
import mmh3
from bitarray import bitarray
import BitVector
import redis
import math
import time
proxies = {'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890'}
class BloomFilter():
SEEDS = [543, 460, 171, 876, 796, 607, 650, 81, 837, 545, 591, 946, 846, 521, 913, 636, 878, 735, 414, 372,
344, 324, 223, 180, 327, 891, 798, 933, 493, 293, 836, 10, 6, 544, 924, 849, 438, 41, 862, 648, 338,
465, 562, 693, 979, 52, 763, 103, 387, 374, 349, 94, 384, 680, 574, 480, 307, 580, 71, 535, 300, 53,
481, 519, 644, 219, 686, 236, 424, 326, 244, 212, 909, 202, 951, 56, 812, 901, 926, 250, 507, 739, 371,
63, 584, 154, 7, 284, 617, 332, 472, 140, 605, 262, 355, 526, 647, 923, 199, 518]
def __init__(self, capacity=1000000000, error_rate=0.00000001, conn=None, key='BloomFilter'):
self.m = math.ceil(capacity*math.log2(math.e)*math.log2(1/error_rate))
self.k = math.ceil(math.log1p(2)*self.m/capacity)
self.mem = math.ceil(self.m/8/1024/1024)
self.blocknum = math.ceil(self.mem/512)
self.seeds = self.SEEDS[0:self.k]
self.key = key
self.N = 2**31-1
self.redis = conn
if not self.redis:
self.bitset = BitVector.BitVector(size=1<<32)
def add(self, value):
name = self.key + "_" + str(ord(value[0])%self.blocknum)
hashs = self.get_hashs(value)
for hash in hashs:
if self.redis:
self.redis.setbit(name, hash, 1)
else:
self.bitset[hash] = 1
def is_exist(self, value):
name = self.key + "_" + str(ord(value[0])%self.blocknum)
hashs = self.get_hashs(value)
exist = True
for hash in hashs:
if self.redis:
exist = exist & self.redis.getbit(name, hash)
else:
exist = exist & self.bitset[hash]
return exist
def get_hashs(self, value):
hashs = list()
for seed in self.seeds:
hash = mmh3.hash(value, seed)
if hash >= 0:
hashs.append(hash)
else:
hashs.append(self.N - hash)
return hashs
class Downloader():
def __init__(self, start_url_list):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
self.r = redis.StrictRedis(host='127.0.0.1', port=6379, db=2, decode_responses=True)
self.bf = BloomFilter(conn=self.r)
for item in start_url_list:
self.r.lpush('url_list', item)
async def get_html(self, url, header=None):
sem = asyncio.Semaphore(100)
try:
async with sem:
async with aiohttp.ClientSession(headers=header, cookies='') as session:
async with session.get(url, proxy='http://127.0.0.1:7890') as resp:
if resp.status in [200, 201]:
data = await resp.text()
return data
else:
return None
except:
return None
def getPDF(self, content, base_url):
pdf = r"href.*\.pdf\""
pdflist = re.findall(pdf, content)
fianl_url_list = []
for item in pdflist:
item_url = item[6:-1]
new_full_url = parse.urljoin(base_url, item_url)
fianl_url_list.append(new_full_url)
return fianl_url_list
def downloadPDF(self, item):
filename = os.path.basename(parse.unquote(item))
cop = re.compile("[^\u4e00-\u9fa5^a-z^A-Z^0-9^\.]")
filename = cop.sub('', filename)
salt = ''.join(["{}".format(random.randint(0, 9)) for num in range(0, 5)])
filename = salt + filename
try:
responsepdf = requests.get(item, proxies=proxies)
if responsepdf.status_code == 200:
with open(r"E:/pdf/%s" % filename, "wb") as code:
code.write(responsepdf.content)
time.sleep(1)
except:
return
def getAllhref(self, html, base_url):
soup = bs(html, features="lxml")
allnode_of_a = soup.find_all("a")
result = [_.get("href").strip() for _ in allnode_of_a if _ is not None and _.get("href") is not None]
filterResult = []
for item in result:
if len(item) > 0:
if item.startswith("http"):
filterResult.append(item)
else:
new_full_url = parse.urljoin(base_url, item)
filterResult.append(new_full_url)
return filterResult
async def start_spider(self):
while True:
cur_url = self.r.rpop('url_list')
if cur_url is None:
break
if self.bf.is_exist(cur_url):
continue
response = await self.get_html(url=cur_url, header=self.headers)
self.bf.add(cur_url)
if response is not None:
pdflist = self.getPDF(response, cur_url)
for item in pdflist:
self.downloadPDF(item)
nextList = self.getAllhref(response, cur_url)
for url in nextList:
self.r.lpush('url_list', url)
async def main():
start_url_list = ["https://github.com/Kensuke-Hinata/statistic/tree/master/os/books"]
downloader = Downloader(start_url_list)
await downloader.start_spider()
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
|